By Ben Dickson
-December 16, 2020

If you’ve been following news about artificial intelligence, you’ve probably heard of or seen modified images of pandas and turtles and stop signs that look ordinary to the human eye but cause AI systems to behave erratically. Known as adversarial examples or adversarial attacks, these images—and their audio and textual counterparts—have become a source of growing interest and concern for the machine learning community.
But despite the growing body of research on adversarial machine learning, the numbers show that there has been little progress in tackling adversarial attacks in real-world applications.
The fast-expanding adoption of machine learning makes it paramount that the tech community traces a roadmap to secure the AI systems against adversarial attacks. Otherwise, adversarial machine learning can be a disaster in the making
.

AI researchers discovered that by adding small black and white stickers to stop signs, they could make them invisible to computer vision algorithms (Source: arxiv.org)
What makes adversarial attacks different?
Every type of software has its own unique security vulnerabilities, and with new trends in software, new threats emerge. For instance, as web applications with database backends started replacing static websites, SQL injection attacks became prevalent. The widespread adoption of browser-side scripting languages gave rise to cross-site scripting attacks. Buffer overflow attacks overwrite critical variables and execute malicious code on target computers by taking advantage of the way programming languages such as C handle memory allocation. Deserialization attacks exploit flaws in the way programming languages such as Java and Python transfer information between applications and processes. And more recently, we’ve seen a surge in prototype pollution attacks, which use peculiarities in the JavaScript language to cause erratic behavior on NodeJS servers.
In this regard, adversarial attacks are no different than other cyberthreats. As machine learning becomes an important component of many applications, bad actors will look for ways to plant and trigger malicious behavior in AI models.
What makes adversarial attacks different, however, is their nature and the possible countermeasures. For most security vulnerabilities, the boundaries are very clear. Once a bug is found, security analysts can precisely document the conditions under which it occurs and find the part of the source code that is causing it. The response is also straightforward. For instance, SQL injection vulnerabilities are the result of not sanitizing user input. Buffer overflow bugs happen when you copy string arrays without setting limits on the number of bytes copied from the source to the destination.
In most cases, adversarial attacks exploit peculiarities in the learned parameters of machine learning models. An attacker probes a target model by meticulously making changes to its input until it produces the desired behavior. For instance, by making gradual changes to the pixel values of an image, an attacker can cause the convolutional neural network to change its prediction from, say, “turtle” to “rifle.” The adversarial perturbation is usually a layer of noise that is imperceptible to the human eye.
(Note: in some cases, such as data poisoning, adversarial attacks are made possible through vulnerabilities in other components of the machine learning pipeline, such as a tampered training data set.)

A neural network thinks this is a picture of a rifle. The human vision system would never make this mistake (source: LabSix)
The statistical nature of machine learning makes it difficult to find and patch adversarial attacks. An adversarial attack that works under some conditions might fail in others, such as a change of angle or lighting conditions. Also, you can’t point to a line of code that is causing the vulnerability because it spread across the thousands and millions of parameters that constitute the model.
Defenses against adversarial attacks are also a bit fuzzy. Just as you can’t pinpoint a location in an AI model that is causing an adversarial vulnerability, you also can’t find a precise patch for the bug. Adversarial defenses usually involve statistical adjustments or general changes to the architecture of the machine learning model.
For instance, one popular method is adversarial training, where researchers probe a model to produce adversarial examples and then retrain the model on those examples and their correct labels. Adversarial training readjusts all the parameters of the model to make it robust against the types of examples it has been trained on. But with enough rigor, an attacker can find other noise patterns to create adversarial examples.
The plain truth is, we are still learning how to cope with adversarial machine learning. Security researchers are used to perusing code for vulnerabilities. Now they must learn to find security holes in machine learning that are composed of millions of numerical parameters.
Growing interest in adversarial machine learning
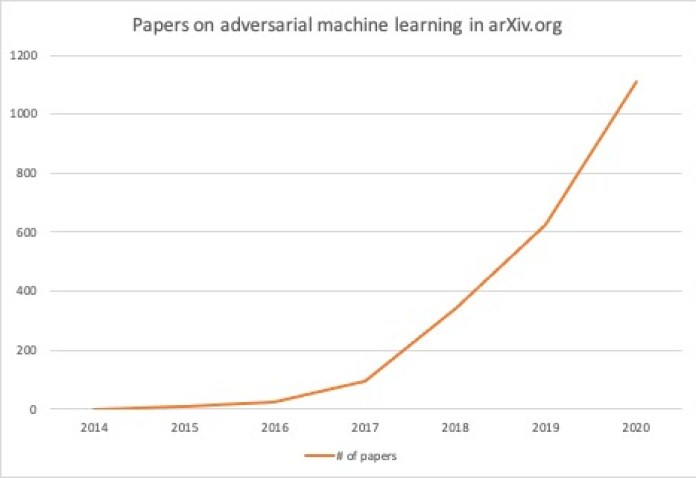
Recent years have seen a surge in the number of papers on adversarial attacks. To track the trend, I searched the arXiv preprint server for papers that mention “adversarial attacks” or “adversarial examples” in the abstract section. In 2014, there were zero papers on adversarial machine learning. In 2020, around 1,100 papers on adversarial examples and attacks were submitted to arxiv.
The statistical nature of machine learning makes it difficult to find and patch adversarial attacks. An adversarial attack that works under some conditions might fail in others, such as a change of angle or lighting conditions. Also, you can’t point to a line of code that is causing the vulnerability because it spread across the thousands and millions of parameters that constitute the model.
Defenses against adversarial attacks are also a bit fuzzy. Just as you can’t pinpoint a location in an AI model that is causing an adversarial vulnerability, you also can’t find a precise patch for the bug. Adversarial defenses usually involve statistical adjustments or general changes to the architecture of the machine learning model.
For instance, one popular method is adversarial training, where researchers probe a model to produce adversarial examples and then retrain the model on those examples and their correct labels. Adversarial training readjusts all the parameters of the model to make it robust against the types of examples it has been trained on. But with enough rigor, an attacker can find other noise patterns to create adversarial examples.
The plain truth is, we are still learning how to cope with adversarial machine learning. Security researchers are used to perusing code for vulnerabilities. Now they must learn to find security holes in machine learning that are composed of millions of numerical parameters.
Growing interest in adversarial machine learning
Recent years have seen a surge in the number of papers on adversarial attacks. To track the trend, I searched the arXiv preprint server for papers that mention “adversarial attacks” or “adversarial examples” in the abstract section. In 2014, there were zero papers on adversarial machine learning. In 2020, around 1,100 papers on adversarial examples and attacks were submitted to arxiv.

From 2014 to 2020, arXiv.org has gone from zero papers on adversarial machine learning to 1,100 papers in one year.
Adversarial attacks and defense methods have also become a key highlight of prominent AI conferences such as NeurIPS and ICLR. Even cybersecurity conferences such as DEF CON, Black Hat, and Usenix have started featuring workshops and presentations on adversarial attacks.
The research presented at these conferences shows tremendous progress in detecting adversarial vulnerabilities and developing defense methods that can make machine learning models more robust. For instance, researchers have found new ways to protect machine learning models against adversarial attacks using random switching mechanisms and insights from neuroscience.
It is worth noting, however, that AI and security conferences focus on cutting edge research. And there’s a sizeable gap between the work presented at AI conferences and the practical work done at organizations every day.
The lackluster response to adversarial attacks
Alarmingly, despite growing interest in and louder warnings on the threat of adversarial attacks, there’s very little activity around tracking adversarial vulnerabilities in real-world applications.
I referred to several sources that track bugs, vulnerabilities, and bug bounties. For instance, out of more than 145,000 records in the NIST National Vulnerability Database, there are no entries on adversarial attacks or adversarial examples. A search for “machine learning” returns five results. Most of them are cross-site scripting (XSS) and XML external entity (XXE) vulnerabilities in systems that contain machine learning components. One of them regards a vulnerability that allows an attacker to create a copy-cat version of a machine learning model and gain insights, which could be a window to adversarial attacks. But there are no direct reports on adversarial vulnerabilities. A search for “deep learning” shows a single critical flaw filed in November 2017. But again, it’s not an adversarial vulnerability but rather a flaw in another component of a deep learning system.
Adversarial attacks and defense methods have also become a key highlight of prominent AI conferences such as NeurIPS and ICLR. Even cybersecurity conferences such as DEF CON, Black Hat, and Usenix have started featuring workshops and presentations on adversarial attacks.
The research presented at these conferences shows tremendous progress in detecting adversarial vulnerabilities and developing defense methods that can make machine learning models more robust. For instance, researchers have found new ways to protect machine learning models against adversarial attacks using random switching mechanisms and insights from neuroscience.
It is worth noting, however, that AI and security conferences focus on cutting edge research. And there’s a sizeable gap between the work presented at AI conferences and the practical work done at organizations every day.
The lackluster response to adversarial attacks
Alarmingly, despite growing interest in and louder warnings on the threat of adversarial attacks, there’s very little activity around tracking adversarial vulnerabilities in real-world applications.
I referred to several sources that track bugs, vulnerabilities, and bug bounties. For instance, out of more than 145,000 records in the NIST National Vulnerability Database, there are no entries on adversarial attacks or adversarial examples. A search for “machine learning” returns five results. Most of them are cross-site scripting (XSS) and XML external entity (XXE) vulnerabilities in systems that contain machine learning components. One of them regards a vulnerability that allows an attacker to create a copy-cat version of a machine learning model and gain insights, which could be a window to adversarial attacks. But there are no direct reports on adversarial vulnerabilities. A search for “deep learning” shows a single critical flaw filed in November 2017. But again, it’s not an adversarial vulnerability but rather a flaw in another component of a deep learning system.

The National Vulnerability Database contains very little information on adversarial attacks
I also checked GitHub’s Advisory database, which tracks security and bug fixes on projects hosted on GitHub. Search for “adversarial attacks,” “adversarial examples,” “machine learning,” and “deep learning” yielded no results. A search for “TensorFlow” yields 41 records, but they’re mostly bug reports on the codebase of TensorFlow. There’s nothing about adversarial attacks or hidden vulnerabilities in the parameters of TensorFlow models.
This is noteworthy because GitHub already hosts many deep learning models and pretrained neural networks.
I also checked GitHub’s Advisory database, which tracks security and bug fixes on projects hosted on GitHub. Search for “adversarial attacks,” “adversarial examples,” “machine learning,” and “deep learning” yielded no results. A search for “TensorFlow” yields 41 records, but they’re mostly bug reports on the codebase of TensorFlow. There’s nothing about adversarial attacks or hidden vulnerabilities in the parameters of TensorFlow models.
This is noteworthy because GitHub already hosts many deep learning models and pretrained neural networks.

GitHub Advisory contains no records on adversarial attacks.
Finally, I checked HackerOne, the platform many companies use to run bug bounty programs. Here too, none of the reports contained any mention of adversarial attacks.
While this might not be a very precise assessment, the fact that none of these sources have anything on adversarial attacks is very telling.
The growing threat of adversarial attacks
Finally, I checked HackerOne, the platform many companies use to run bug bounty programs. Here too, none of the reports contained any mention of adversarial attacks.
While this might not be a very precise assessment, the fact that none of these sources have anything on adversarial attacks is very telling.
The growing threat of adversarial attacks

Adversarial vulnerabilities are deeply embedded in the many parameters of machine learning models, which makes it hard to detect them with traditional security tools.
Automated defense is another area that is worth discussing. When it comes to code-based vulnerabilities Developers have a large set of defensive tools at their disposal.
Static analysis tools can help developers find vulnerabilities in their code. Dynamic testing tools examine an application at runtime for vulnerable patterns of behavior. Compilers already use many of these techniques to track and patch vulnerabilities. Today, even your browser is equipped with tools to find and block possibly malicious code in client-side script.
At the same time, organizations have learned to combine these tools with the right policies to enforce secure coding practices. Many companies have adopted procedures and practices to rigorously test applications for known and potential vulnerabilities before making them available to the public. For instance, GitHub, Google, and Apple make use of these and other tools to vet the millions of applications and projects uploaded on their platforms.
But the tools and procedures for defending machine learning systems against adversarial attacks are still in the preliminary stages. This is partly why we’re seeing very few reports and advisories on adversarial attacks.
Meanwhile, another worrying trend is the growing use of deep learning models by developers of all levels. Ten years ago, only people who had a full understanding of machine learning and deep learning algorithms could use them in their applications. You had to know how to set up a neural network, tune the hyperparameters through intuition and experimentation, and you also needed access to the compute resources that could train the model.
But today, integrating a pre-trained neural network into an application is very easy.
For instance, PyTorch, which is one of the leading Python deep learning platforms, has a tool that enables machine learning engineers to publish pretrained neural networks on GitHub and make them accessible to developers. If you want to integrate an image classifier deep learning model into your application, you only need a rudimentary knowledge of deep learning and PyTorch.
Since GitHub has no procedure to detect and block adversarial vulnerabilities, a malicious actor could easily use these kinds of tools to publish deep learning models that have hidden backdoors and exploit them after thousands of developers integrate them in their applications.
Automated defense is another area that is worth discussing. When it comes to code-based vulnerabilities Developers have a large set of defensive tools at their disposal.
Static analysis tools can help developers find vulnerabilities in their code. Dynamic testing tools examine an application at runtime for vulnerable patterns of behavior. Compilers already use many of these techniques to track and patch vulnerabilities. Today, even your browser is equipped with tools to find and block possibly malicious code in client-side script.
At the same time, organizations have learned to combine these tools with the right policies to enforce secure coding practices. Many companies have adopted procedures and practices to rigorously test applications for known and potential vulnerabilities before making them available to the public. For instance, GitHub, Google, and Apple make use of these and other tools to vet the millions of applications and projects uploaded on their platforms.
But the tools and procedures for defending machine learning systems against adversarial attacks are still in the preliminary stages. This is partly why we’re seeing very few reports and advisories on adversarial attacks.
Meanwhile, another worrying trend is the growing use of deep learning models by developers of all levels. Ten years ago, only people who had a full understanding of machine learning and deep learning algorithms could use them in their applications. You had to know how to set up a neural network, tune the hyperparameters through intuition and experimentation, and you also needed access to the compute resources that could train the model.
But today, integrating a pre-trained neural network into an application is very easy.
For instance, PyTorch, which is one of the leading Python deep learning platforms, has a tool that enables machine learning engineers to publish pretrained neural networks on GitHub and make them accessible to developers. If you want to integrate an image classifier deep learning model into your application, you only need a rudimentary knowledge of deep learning and PyTorch.
Since GitHub has no procedure to detect and block adversarial vulnerabilities, a malicious actor could easily use these kinds of tools to publish deep learning models that have hidden backdoors and exploit them after thousands of developers integrate them in their applications.
How to address the threat of adversarial attacks

Understandably, given the statistical nature of adversarial attacks, it’s difficult to address them with the same methods used against code-based vulnerabilities. But fortunately, there have been some positive developments that can guide future steps.
The Adversarial ML Threat Matrix, published last month by researchers at Microsoft, IBM, Nvidia, MITRE, and other security and AI companies, provides security researchers with a framework to find weak spots and potential adversarial vulnerabilities in software ecosystems that include machine learning components. The Adversarial ML Threat Matrix follows the ATT&CK framework, a known and trusted format among security researchers.
Another useful project is IBM’s Adversarial Robustness Toolbox, an open-source Python library that provides tools to evaluate machine learning models for adversarial vulnerabilities and help developers harden their AI systems.
These and other adversarial defense tools that will be developed in the future need to be backed by the right policies to make sure machine learning models are safe. Software platforms such as GitHub and Google Play must establish procedures and integrate some of these tools into the vetting process of applications that include machine learning models. Bug bounties for adversarial vulnerabilities can also be a good measure to make sure the machine learning systems used by millions of users are robust.
New regulations for the security of machine learning systems might also be necessary. Just as the software that handles sensitive operations and information is expected to conform to a set of standards, machine learning algorithms used in critical applications such as biometric authentication and medical imaging must be audited for robustness against adversarial attacks.
As the adoption of machine learning continues to expand, the threat of adversarial attacks is becoming more imminent. Adversarial vulnerabilities are a ticking timebomb. Only a systematic response can defuse it.
Ben Dickson
Ben is a software engineer and the founder of TechTalks. He writes about technology, business and politics.
No comments:
Post a Comment