It’s possible that I shall make an ass of myself. But in that case one can always get out of it with a little dialectic. I have, of course, so worded my proposition as to be right either way (K.Marx, Letter to F.Engels on the Indian Mutiny)
Saturday, January 24, 2026
Computing using real life traffic, novel approach to AI cuts its energy usage
Advanced Institute for Materials Research (AIMR), Tohoku University
What if traffic could compute? This may sound strange, but researchers at Tohoku University's WPI-AIMR have unveiled a bold new idea: using road traffic itself as a computer.
Researchers at the Advanced Institute for Materials Research (WPI-AIMR), Tohoku University, have proposed a novel artificial intelligence (AI) framework that treats road traffic itself as a computing resource. The approach, called Harvested Reservoir Computing (HRC), opens up a path toward energy-efficient AI systems that reuse the dynamics already existing in our environment instead of relying solely on power-hungry dedicated hardware.
Their AI framework, called Harvested Reservoir Computing, taps into the natural dynamics of traffic flow to enable energy-efficient AI - turning everyday motion into computational power without energy-hungry hardware.
In recent years, machine learning and deep learning have been widely applied to traffic forecasting, demand prediction, and various forms of social infrastructure management. However, these approaches typically require massive computational power and large energy consumption. Reservoir computing (RC), and its extension to real-world physical systems - physical reservoir computing (PRC) - have attracted attention as promising alternatives.
Building on this concept, Professor Hiroyasu Ando and colleagues propose HRC, a framework that "harvests" complex physical dynamics present in the natural and social environment and uses them directly for computation. As a proof of concept, the team systematically evaluated the performance of Road Traffic Reservoir Computing (RTRC), which exploits traffic flow on road networks as a computational reservoir.
Combining controlled traffic experiments using 1/27-scale autonomous miniature cars with numerical simulations of grid-shaped urban road networks, the researchers discovered a striking feature: prediction accuracy is not highest under free-flow or heavily congested conditions. Instead, it peaks just before congestion begins, at a critical, medium-density state where traffic dynamics are most diverse and informative. In this regime, the traffic system naturally processes incoming information, allowing accurate forecasts of future traffic states with minimal computational overhead.
Importantly, this method requires no new specialized hardware. By reusing existing traffic sensors and observational data, it has the potential to support high-precision traffic prediction and adaptive signal control while significantly reducing energy consumption compared with conventional AI approaches.
The study suggests that social infrastructure such as roads can be reinterpreted as "large-scale, continuously operating computers." Beyond traffic management, the concept may enable future applications in smart mobility, urban planning, and energy management, where environmental dynamics are leveraged as part of the computational process.
"These results demonstrate that computation does not have to be confined to silicon chips," says Ando. "By recognizing and harnessing the rich dynamics already present in our environment, we may build AI systems that are both powerful and sustainable."
The research also contributes a new perspective to the development of AI foundation technologies: rather than endlessly scaling up hardware, it may be possible to scale intelligence by integrating physical systems and data in innovative ways.
The findings were published online in Scientific Reports on November 27, 2025.
About the World Premier International Research Center Initiative (WPI)
The WPI program was launched in 2007 by Japan's Ministry of Education, Culture, Sports, Science and Technology (MEXT) to foster globally visible research centers boasting the highest standards and outstanding research environments. Numbering more than a dozen and operating at institutions throughout the country, these centers are given a high degree of autonomy, allowing them to engage in innovative modes of management and research. The program is administered by the Japan Society for the Promotion of Science (JSPS).
Establishing a World-Leading Research Center for Materials Science
AIMR aims to contribute to society through its actions as a world-leading research center for materials science and push the boundaries of research frontiers. To this end, the institute gathers excellent researchers in the fields of physics, chemistry, materials science, engineering, and mathematics and provides a world-class research environment.
In a Policy Forum, Daniel Schroeder and colleagues discuss the risks of malicious “Artificial Intelligence (AI) swarms”, which enable a new class of large-scale, coordinated disinformation campaigns that pose significant risks to democracy. Manipulation of public opinion has long relied on rhetoric and propaganda. However, modern AI systems have created powerful new tools for shaping human beliefs and behavior on a societal scale. Large language models (LLMs) and autonomous agents can now generate vast amounts of persuasive, human-like content. When combined into collaborative AI Swarms – collections of AI-driven personas that retain memory and identity – these systems can mimic social dynamics and easily infiltrate online communities, making false narratives appear credible and widely shared. According to the authors, unlike earlier labor-intensive influence operations run by humans, AI systems can operate cheaply, consistently, and at tremendous scale, transforming once isolated disinformation efforts into persistent, adaptive campaigns that pose serious risks to democratic processes worldwide. Here, Schroeder et al. discuss the technology underpinning these malicious systems and identify pathways through which they can harm democratic discourse through widely used digital platforms. The authors argue that defense against these systems must be layered and pragmatic, aiming not for total prevention of their use, which is highly unlikely, but for raising the cost, risk, and visibility of manipulation. Because such efforts would require global coordination outside of corporate and governmental interests, Schroeder et al. propose a distributed “AI Influence Observatory,” consisting of a network of academic groups, nongovernmental organizations, and other civil institutions to guide independent oversight and action. “Success depends on fostering collaborative action without hindering scientific research while ensuring that the public sphere remains both resilient and accountable,” write the authors. “By committing now to rigorous measurement, proportionate safeguards, and shared oversight, upcoming elections could even become a proving ground for, rather than a setback to, democratic AI governance.”
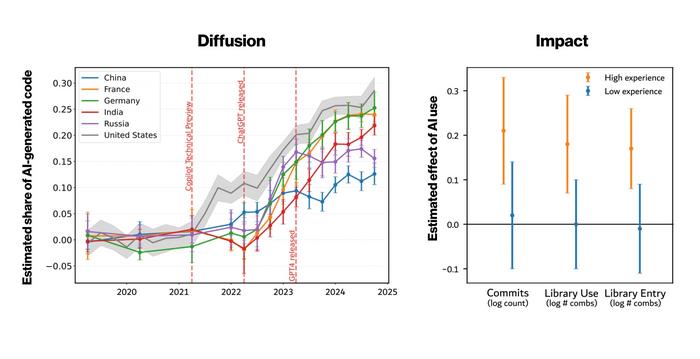
Left: The share of AI-written Python functions (2019-2024) grows rapidly, but countries differ in their adoption rates. The U.S. leads the early adoption of generative AI, followed by European nations such as France and Germany. From 2023 onward, India rapidly catches up, whereas adoption in China and Russia progresses more slowly. Right: Comparing usage rates for the same programmers at different points in time, generative AI adoption is associated with increased productivity (commits), breadth of functionality (library use) and exploration of new functionality (library entry), but only for senior developers, while early-career developers do not derive any statistically significant benefits from using generative AI.
Generative AI is reshaping software development – and fast. A new study published in Science shows that AI-assisted coding is spreading rapidly, though unevenly: in the U.S., the share of new code relying on AI rose from 5% in 2022 to 29% in early 2025, compared with just 12% in China. AI usage is highest among less experienced programmers, but productivity gains go to seasoned developers.
The software industry is enormous. In the U.S. economy alone, firms spend an estimated $600 billion a year in wages on coding-related work. Every day, billions of lines of code keep the global economy running. How is AI changing this backbone of modern life?
In a study published in Science, a research team led by the Complexity Science Hub (CSH) found that by the end of 2024, around one-third of all newly written software functions – self-contained subroutines in a computer program – in the United States were already being created with the support of AI systems.
“We analyzed more than 30 million Python contributions from roughly 160,000 developers on GitHub, the world’s largest collaborative programming platform,” says Simone Daniotti of CSH and Utrecht University. GitHub records every step of coding – additions, edits, improvements – allowing researchers to track programming work across the globe in real time. Python is one of the most widely used programming languages in the world.
REGIONAL GAPS ARE LARGE
The team used a specially trained AI model to identify whether blocks of code were AI-generated, for instance via ChatGPT or GitHub Copilot.
“The results show extremely rapid diffusion,” explains Frank Neffke, who leads the Transforming Economies group at CSH. “In the U.S., AI-assisted coding jumped from around 5% in 2022 to nearly 30% in the last quarter of 2024.”
At the same time, the study found wide differences across countries. “While the share of AI-supported code is highest in the U.S. at 29%, Germany reaches 23% and France 24%, followed by India at 20%, which has been catching up fast,” he says, while Russia (15%) and China (12%) still lagged behind at the end of the study.
“It's no surprise the U.S. leads – that's where the leading LLMs come from. Users in China and Russia have faced barriers to accessing these models, blocked by their own governments or by the providers themselves, though VPN workarounds exist. Recent domestic Chinese breakthroughs like DeepSeek, released after our data ends in early 2025, suggest this gap may close quickly,” says Johannes Wachs, a faculty member at CSH and associate professor at Corvinus University of Budapest.
EXPERIENCED DEVELOPERS BENEFIT MOST
The study shows that the use of generative AI increased programmers’ productivity by 3.6% by the end of 2024. “That may sound modest, but at the scale of the global software industry it represents a sizeable gain,” says Neffke, who is also a professor at Interdisciplinary Transformation University Austria (IT:U).
The study finds no differences in AI usage between women and men. By contrast, experience levels matter: less experienced programmers use generative AI in 37% of their code, compared to just 27% for experienced programmers. Despite this, the productivity gains the study documents are driven exclusively by experienced users. "Beginners hardly benefit at all," says Daniotti. Generative AI therefore does not automatically level the playing field; it can widen existing gaps.
In addition, experienced software developers experiment more with new libraries and unusual combinations of existing software tools. "This suggests that AI does not only accelerate routine tasks, but also speeds up learning, helping experienced programmers widen their capabilities and more easily venture into new domains of software development," says Wachs.
ECONOMIC GAINS
What does all of this mean for the economy? “The U.S. spends an estimated $637 billion to $1.06 trillion annually in wages on programming tasks, according to an analysis of about 900 different occupations,” says co-author Xiangnan Feng from CSH. If 29% of code is AI-assisted and productivity rises by 3.6%, that adds between $23 and $38 billion in value each year. “This is likely a conservative estimate,” Neffke points out, “the economic impact of generative AI in software development was already substantial at the end of 2024 and is likely to have increased further since our analysis.”
LOOKING AHEAD
Software development is undergoing profound transformation. AI is becoming central to digital infrastructure, boosting productivity and fostering innovation – but mainly for people who already have substantial work experience.
“For businesses, policymakers, and educational institutes, the key question is not whether AI will be used, but how to make its benefits accessible without reinforcing inequalities,” says Wachs. “When even a car has essentially become a software product, we need to understand the hurdles to AI adoption – at the company, regional, and national levels – as quickly as possible,” Neffke adds.
In April 2025, OpenAI’s popular ChatGPT hit a milestone of a billion active weekly users, as artificial intelligence continued its explosion in popularity.
But with that popularity has come a dark side. Biases in AI’s models and algorithms can actively harm some of its users and promote social injustice. Documented biases have led to different medical treatments due to patients’ demographics and corporate hiring tools that discriminate against female and Black candidates.
New research from Texas McCombs suggests both a previously unexplored source of AI biases and some ways to correct for them: complexity.
“There’s a complex set of issues that the algorithm has to deal with, and it’s infeasible to deal with those issues well,” says Hüseyin Tanriverdi, associate professor of information, risk, and operations management. “Bias could be an artifact of that complexity rather than other explanations that people have offered.”
With John-Patrick Akinyemi, a McCombs Ph.D. candidate in IROM, Tanriverdi studied a set of 363 algorithms that researchers and journalists had identified as biased. The algorithms came from a repository called AI Algorithmic and Automation Incidents and Controversies.
The researchers compared each problematic algorithm with one that was similar in nature but had not been called out for bias. They examined not only the algorithms but also the organizations that created and used them.
Prior research has assumed that bias can be reduced by making algorithms more accurate. But that assumption, Tanriverdi found, did not tell the whole story. He found three additional factors, all related to a similar problem: not properly modeling for complexity.
Ground truth. Some algorithms are asked to make decisions when there’s no established ground truth: the reference against which the algorithm’s outcomes are evaluated. An algorithm might be asked to guess the age of a bone from an X-ray image, even though in medical practice, there’s no established way for doctors to do so.
In other cases, AI may mistakenly treat opinions as objective truths — for example, when social media users are evenly split on whether a post constitutes hate speech or protected free speech.
AI should only automate decisions for which ground truth is clear, Tanriverdi says. “If there is not a well-established ground truth, then the likelihood that bias will emerge significantly increases.”
Real-world complexity. AI models inevitably simplify the situations they describe. Problems can arise when they miss important components of reality.
Tanriverdi points to a case in which Arkansas replaced home visits by nurses with automated rulings on Medicaid benefits. It had the effect of cutting off disabled people from assistance with eating and showering.
“If a nurse goes and walks around to the house, they will be able to understand more about what kind of support this person needs,” he says. “But algorithms were using only a subset of those variables, because data was not available on everything.
“Because of omission of the relevant variables in the model, that model was no longer a good enough representation of reality.”
Stakeholder involvement. When a model serving a diverse population is designed mostly by members of a single demographic, it becomes more susceptible to bias. One way to counter this risk is to ensure that all stakeholder groups have a voice in the development process.
By involving stakeholders who may have conflicting goals and expectations, an organization can determine whether it’s possible to meet them all. If it’s not, Tanriverdi says, “It may be feasible to reach compromise solutions that everyone is OK with.”
The research concludes that taming AI bias involves much more than making algorithms more accurate. Developers need to open up their black boxes to account for real-world complexities, input from diverse groups, and ground truths.
“The factors we focus on have a direct effect on the fairness outcome,” Tanriverdi says. “These are the missing pieces that data scientists seem to be ignoring.”
Researchers fabricated an AI-driven dating website that delivered below or beyond expectations of the user. They found that how expectations were matched — or mismatched — correlated to whether the user wanted to better understand how the AI system worked.
UNIVERSITY PARK, Pa. — Artificial intelligence (AI) is said to be a “black box,” with its logic obscured from human understanding — but how much does the average user actually care to know how AI works? It depends on the extent to which a system meets users’ expectations, according to a new study by a team that includes Penn State researchers. Using a fabricated algorithm-driven dating website, the team found that whether the system met, exceeded or fell short of user expectations directly corresponded to how much the user trusted the AI and wanted to know about how it worked.
The study is available online ahead of publication in the April 2026 issue of the journal Computers in Human Behavior. The findings have implications for companies across industries, including health care and finance, that are developing such systems to better understand what users want to know and to deliver useful information in a comprehensible way, according to co-author S. Shyam Sundar, Evan Pugh University Professor and James P. Jimirro Professor of Media Ethics in the Penn State Donald P. Bellisario College of Communications.
“AI can create all kinds of soul searching for people — especially in sensitive personal domains like online dating,” said Sundar, who directs the Penn State Center for Socially Responsible Artificial Intelligence and co-directs the Media Effects Research Laboratory. “There’s uncertainty in how algorithms produce what they produce. If a dating algorithm suggests fewer matches than expected, users may think something is wrong with them, but if suggests more matches than expected, then they might think that their dating criteria are too broad and indiscriminate.”
In this study, 227 participants in the United States who reported being single answered questions at smartmatch.com, a fictitious dating site created by the researchers for the study. Each participant was assigned to one of nine potential testing conditions and directed to answer typical dating site questions about their interests and traits they find desirable in others. The site then told them that it would provide 10 potential matches on their “Discover Page” and that it “normally generates five ‘Top Picks’ for each user.” Depending on the testing condition, the participant would see either the five mentioned “Top Picks” with a message confirming that five options was the norm, or a variation accompanied by a message noting that while five options was typical, this time the system found two or 10.
“If someone expect five matches, but get two or 10, then a user may think they’ve done something wrong or that something is wrong with them,” said lead author Yuan Sun, assistant professor in the University of Florida’s College of Journalism and Communications. Advised by Sundar, she earned her doctorate from Penn State in 2023. “If the system works fine, you just go along with it; you don’t need a long explanation. But what do you need if your expectations are unmet? The broader issue here is transparency.”
That may be different than how humans respond when other humans defy expectations, according to co-author Joseph B. Walther, Bertelsen Presidential Chair in Technology and Society and distinguished professor of communication at the University of California, Santa Barbara, who has long studied expectancy violations in interpersonal settings. When humans violate expectations, surprised victims tend to make judgments about the violator, increase or decrease how much they like them, and approach or avoid them thereafter.
“Being able to find out ‘why the surprise?’ is a luxury and source of satisfaction,” he said, explaining that asking another person why they behaved as they did is intrusive and potentially awkward. “But it appears that we’re unafraid to ask the intelligent machine for an explanation.”
Participants in the study had the opportunity to request more information about their results and then rate their trust in the system. The researchers found that when the system met expectations — delivering the promised five top picks — participants reported trusting the system without needing an explanation of the AI’s inner workings. When the system overdelivered, a simple explanation to clarify the mismatched expectations bolstered user trust in the algorithm. However, when the system underdelivered, users required a more detailed explanation.
“Many developers talk about making AI more transparent and understandable by providing specific information,” Sun said. “There is far less discussion about when those explanations are necessary and how much should be presented. That’s the gap we’re interested in filling.”
The researchers pointed to how many social media apps already provide an option for users to learn more about the systems in place, but they’re relatively standardized, use technical language and are buried in the fine print of broader user agreements.
“Tons of studies show that these explanations don’t work well. They’re not effective in the goal of transparency to enhance user experience and trust,” Sundar said, noting that many of the current explanations are treated like disclaimers. “No one really benefits. It’s due diligence rather than being socially responsible.”
Sun noted that the bulk of scientific literature reports that the better a site performs, the more people trust it. Yet, these findings suggested that wasn’t the case: People still wanted to understand the reasoning, even if they were given far more top picks than promised.
“Good is good, so we thought people would be satisfied with face value, but they weren’t. They were curious,” Sun said. “It’s not just performance; it’s transparency. Higher transparency gives people more understanding of the system, leading to higher trust.”
However, as more industries adopt AI, the researchers said simple transparency is not sufficient.
“We can’t just say there’s information in the terms and conditions, and that absolves us,” Sun said. “We need more user-centered, tailored explanations to help people better understand AI systems when they want it and in a way that meets their needs. This study opens the door to more research that could help achieve that.”
Mengqi “Maggie” Liao, University of Georgia, also collaborated on this project.
Aerial photo of the Innovative Technologies Complex with (from left) the Smart Energy Building, Center of Excellence Building, Biotechnology Building and the Engineering and Science Building.
Credit: Binghamton University, State University of New York
Thanks to a historic academic gift – the largest in University history – Binghamton is poised to become a national leader in responsible artificial intelligence.
A record-setting $55 million commitment from a Binghamton University alumnus and New York state will establish the Center for AI Responsibility and Research, the first-ever independent AI research center at a public university in the United States. Research conducted via the new center will build upon Binghamton research that advances AI for the public good.
Part of the Empire AI project, an initiative to establish New York as a leader in responsible AI research and development, the center will be supported by a $30 million commitment from Tom Secunda '76, MA '79, co-founder of Bloomberg LP, who is a key private sector partner and philanthropist involved in Gov. Hochul's Empire AI consortium. This will be coupled with a $25 million capital investment from Gov. Hochul and the New York State Legislature.
“The Center for AI Responsibility and Research will bring together innovative research and scholarship, ethical leadership and public engagement at a moment when all three are urgently needed,” said President Anne D’Alleva. “I am deeply grateful to Governor Hochul and the State Legislature for their visionary support, and to Tom Secunda for his extraordinary generosity and continued commitment to his alma mater. Together, we are creating a research environment that ensures AI will strengthen communities, build our economy, and earn the public’s trust.”
“Artificial intelligence is advancing rapidly, and as the technology influences everything we do, we need to be just as nimble in making sure AI works for New Yorkers safely and responsibly,” Gov. Hochul said. “The Center for AI Responsibility and Research will be that independent arm of research that gives New Yorkers transparency to ensure AI is used for the public good.”
Binghamton University is one of the first members of the Empire AI Consortium, whose campus researchers are using Empire Alpha, the supercomputer housed at the State University of New York at Buffalo, until the full-scale Empire AI computing is completed. Binghamton has 10 projects approved, led by faculty researchers and their students utilizing Empire Alpha and working to advance AI for the public good in New York.
“SUNY is on the move, and thanks to Gov. Hochul and our State Legislature, and private donors like Tom Secunda, our talented faculty members and students are being equipped with a top-tier independent research environment to support our efforts and move New York forward,” said SUNY Chancellor John B. King Jr. “This historic investment is part of Governor Hochul’s ongoing commitment to double research at SUNY and ensure we are at the cutting edge of emerging technologies, including AI. There’s truly no better place for this work than right here in the SUNY family.”
The center will build upon the research of Binghamton faculty, who are using machine learning and data science to solve real-world challenges – everything from delivering better healthcare to improving information security. Most recently, Yu Chen, professor of electrical and computer engineering, won $50,000 from the SUNY Technology Accelerator Fund (TAF) to support the development of technology that flags deepfake content and AI images.
“Responsible AI is about making technology that we can trust, and our SUNY campuses have the best tools to offer our outstanding faculty and aspiring student researchers,” said the SUNY Board of Trustees. “Our deep thanks to Gov. Hochul, state leaders, and Tom Secunda for their outstanding commitment to AI research and innovation.”
The Institute of Science and Technology Austria (ISTA) receives €5 million donation for AI research
Uber co-founder Canadian Garrett Camp's first gift to a European institute shows ISTA’s global appeal
Martin Hetzer, president of the Institute of Science and Technology Austria (ISTA), looks on as Canadian philanthropist, entrepreneur and Uber co-founder Garrett Camp signs an agreement to donate €5 million to ISTA for AI research.
The Institute of Science and Technology Austria (ISTA) has received a donation of 5 million euros from Canadian philanthropist and entrepreneur Garrett Camp to help advance AI as a trustworthy, human-centered technology that benefits society. ISTA’s commitment to responsible AI, coupled with its focus on frontier research and interdisciplinary culture, make it perfectly placed to pursue this goal.
Camp – who is the creator of the not-for-profit Camp.org research organization and co-founder of the ride-hailing Uber app – visited the ISTA campus on January 13 to sign the donation agreement with President Martin Hetzer and Managing Director Georg Schneider.
“With this generous gift, ISTA can further build upon fundamental research in artificial intelligence, drawing on our strengths in computer science, mathematics, and the natural sciences,” said Hetzer. “It helps us pursue AI research within a broad, interdisciplinary scientific context, deepen our understanding of how these systems work, and address their limitations. It is essential for developing robust and trustworthy AI systems that deliver long-term value for both science and society.”
Investment in future breakthroughs
For Camp, the ISTA donation reflects a belief that the next generation of AI breakthroughs will come from ecosystems that prioritize rigor, collaboration, and long-term impact over short-term speed. His current focus is centered around facilitating AI development that helps people thrive around the world.
“Global solutions demand global perspectives and collaboration,” said Camp. “Supporting ISTA is about investing in a community that unites brilliant minds from around the world to further advance trustworthy AI in harmony with humanity and helps to ensure that innovation continues to grow with integrity, transparency, and respect for human values." Camp has a history of supporting non-profit organizations focused on building responsible and trustworthy AI technology. However, the ISTA gift represents his first contribution to a European research institution.
"We are thrilled to have played a role in helping bring these two institutions together,” said Niklas Schmidt of Wolf Theiss Attorneys-at-Law. “Camp's donation acknowledges the excellence of the Austrian research landscape."
ISTA as AI hub
ISTA’s work in AI is wide-ranging and focuses on building systems that are reliable, efficient and scientifically grounded. Key areas include trustworthy AI, with researchers such as Christoph Lampert and his team striving for principled solutions rather than just bug fixes while seeking to make AI safer, as well as more robust, fair and respectful of data privacy.
Sustainable AI is another ISTA focus, with research led by Dan Alistarh aimed at making AI models more resource-efficient and broadly accessible. Francesco Locatello and his team work on causal AI aimed at helping AI systems learn how causes lead to effects, how actions change outcomes and how data they encounter can shift over time.
At ISTA, AI is also closely integrated with other research fields. That includes experimentally aware AI for protein structure prediction. In this area, Alex Bronstein, in collaboration with Paul Schanda, developed a method to ‘guide’ the AlphaFold3 AI model to match experimental data. Monika Henzinger meanwhile pursues work on the privacy-preserving training of large language models while Marco Mondelli and his group have developed rigorous methods for exploiting massive datasets and solving complex inference problems.
Bolstered by the donation, these and other ISTA researchers including Krishnendu Chatterjee, Thomas Henzinger, and Matthew Robinson will continue to contribute to AI research that is both scientifically robust and socially responsible.
“We greatly value this transatlantic vote of confidence in ISTA’s research mission and in our role in shaping the future of AI,” Hetzer said.
Since opening its doors in 2009, ISTA has attracted scientists from around the world who carry out foundational research spanning the natural sciences, mathematics and computer science across roughly 90 groups, with that number expected to increase to 150 over the next decade.
The Institute of Science and Technology Austria (ISTA) near Vienna draws scientists from around the world who carry out curiosity-driven research spanning the natural sciences, mathematics and computer science across roughly 90 groups, with that number expected to increase to 150 over the next decade.
The campus of the Institute of Science and Technology Austria (ISTA) as seen from above. Located near Vienna, ISTA draws scientists from around the world who carry out curiosity-driven research spanning the natural sciences, mathematics and computer science across roughly 90 groups, with that number expected to increase to 150 over the next decade.
Martin Hetzer, president of the Institute of Science and Technology Austria (ISTA), and Canadian philanthropist, entrepreneur and Uber co-founder Garrett Camp on ISTA's campus. Camp visited ISTA to make a €5 million donation to advance AI as a trustworthy, human-centered technology that benefits society.
This survey study found that artificial intelligence (AI) use was significantly associated with greater depressive symptoms, with magnitude of differences varying by age group. Further work is needed to understand whether these associations are causal and explain heterogeneous effects.
Corresponding Author: To contact the corresponding author, Roy H. Perlis, MD, MSc, email rperlis@mgb.org.
Editor’s Note: Please see the article for additional information, including other authors, author contributions and affiliations, conflict of interest and financial disclosures, and funding and support.
# # #
Embed this link to provide your readers free access to the full-text article
About JAMA Network Open: JAMA Network Open is an online-only open access general medical journal from the JAMA Network. On weekdays, the journal publishes peer-reviewed clinical research and commentary in more than 40 medical and health subject areas. Every article is free online from the day of publication.
Journal
JAMA Network Open
Insilico Medicine launches science MMAI gym to train frontier LLMs into pharmaceutical-grade scientific engines
New “AI GYM for Science” dramatically boosts the biological and chemical intelligence of any causal or frontier LLM, delivering up to 10x performance gains on key drug discovery benchmarks and advancing the company’s vision of Pharmaceutical Superintelligence (PSI).
New “AI GYM for Science” dramatically boosts the biological and chemical intelligence of any causal or frontier LLM, delivering up to 10x performance gains on key drug discovery benchmarks and advancing the company’s vision of Pharmaceutical Superintelligence (PSI).
CAMBRIDGE, Mass., January 22, 2026 – Insilico Medicine (“Insilico”, HKEX: 3696), a leading global AI-driven biotech company, today announced the launch of Science MMAI Gym, also branded as Insilico Medicine’s AI GYM for Science, a domain-specific training environment designed to transform any causal or frontier large language model (LLM) into a high-performance engine for real-world drug discovery and development tasks.
Building on more than a decade of AI research and its own internal pipeline of 27 preclinical candidates, 10+ molecules with IND clearance, and multiple Phase I and Phase IIa clinical trials completed or ongoing, Insilico is now opening its AI training infrastructure to external partners. Science MMAI Gym adapts and optimizes general-purpose LLMs, such as GPT, Claude, Gemini, Grok, Llama, Mistral and others, to reason in medicinal chemistry, biology, and clinical development with the precision required in modern pharma R&D.
Science MMAI Gym is a core component of Insilico’s long-term roadmap toward Pharmaceutical Superintelligence (PSI), with dedicated tracks for Chemical Superintelligence (CSI) and Biology/Clinical Superintelligence (BSI). Over a period of weeks to months, partner models “train” in the Gym using curated domain-specific reasoning datasets across multiple relevant domains and tasks, reward models, and reinforcement learning with domain-specific reasoning, and emerge with up to 10x improvements in performance on key chemistry and biology benchmarks, in some cases matching or approaching state of the art (SOTA) specialist models across multiple tasks, all with a single-model-does-it-all approach.
Boosting Frontier LLMs’ Biological and Chemical Intelligence
Despite their impressive general reasoning capabilities, flagship LLMs still underperform or fail on many mission-critical drug discovery tasks. As shown in benchmark comparisons assembled by Insilico, leading models struggle to accurately predict pharmacokinetic and toxicity endpoints, such as Caco-2 permeability, plasma protein binding, tissue distribution (VDss), half-life, microsomal and hepatocyte clearance, hERG and DILI risk, or LD50, when evaluated on the open Therapeutics Data Commons (TDC) benchmark suite. In several tasks, their mean absolute error (MAE) is orders of magnitude above practical SOTA targets, or their classification metrics, such as balanced accuracy (BA) and area under the ROC or precision-recall curve (AUROC/AUPRC), fall well below thresholds typically expected for preclinical decision-making.
The problem is not solved by better prompts alone. Even with 5 few-shot examples with in-context learning and rich task descriptions, general models often default to vague or chemically and biologically implausible reasoning. Simple fine-tuning on the training split of a benchmark can offer incremental improvements but rarely produces SOTA models which should operate robustly in the wild on out-of-distribution compounds and novel targets.
Science MMAI Gym addresses this gap directly. Rather than treating drug discovery as just another NLP benchmark, the Gym teaches LLMs domain-specific scientific reasoning, the language, formats, and conceptual chains that chemists, biologists, and clinicians actually use:
Medicinal and organic chemistry: multi-step optimization chains, reaction reasoning, retrosynthesis templates, structure-property relationships, and 3D binding interactions.
Biology and target discovery: omics-aware reasoning over gene expression, pathways, disease mechanisms, and multi-objective target scoring.
Clinical development: interpretation of trial designs, endpoints, response biomarkers, and prediction of success or failure of Phase 2 trials using proprietary benchmarks such as ClinBench.
On-demand high-quality reasoning data generation: the validated simulation/data generation models widely used in Chemistry42 and PandaOmics products generate as many reasoning traces as needed to teach the LLMs to reason, predict, create novel compounds, and optimize relevant properties.
Foundation Models for Drug Discovery: Insilico’s Starting Point
Science MMAI Gym is built on Insilico’s established portfolio of foundation models for chemistry and biology. These include:
Natural Language and Chemistry LLM (Nach0 / Nach01), co-developed with NVIDIA a multi-domain encoder-decoder model trained on unlabeled scientific text, patents, molecule strings, and diverse chemistry datasets. It supports biomedical question answering, named entity recognition, molecular generation, reaction prediction, multi-step retrosynthesis, molecular property prediction, quantum property prediction, and cross-domain tasks such as description-to-molecule/protein and protein-to-description.
Proof-of-concept language models for 3D drug design, such as nach0-pc and BindGPT, published at AAAI 2025. These models demonstrated that LMs can perform shape- and pocket-conditioned 3D generation, linker design, scaffold decoration, conformer generation, and reinforcement-learning-driven 3D molecular design, at times outperforming specialized diffusion models.
These foundation models already operate on 2D and 3D small molecules, 1D and 3D protein structures, and multiple cross-modal tasks. Science MMAI Gym generalizes and industrializes this work: instead of a single research model, it offers a systematic environment where any causal LM can be adapted into a domain-specific scientific copilot.
How Insilico’s Models Compare to Frontier LLMs
Insilico’s internal benchmarking shows that its specialized models consistently outperform general LLMs on drug discovery tasks:
On TDC ADMET tasks, Insilico’s Nach01-1B-1 model for chemistry achieves substantially lower MAE for key properties like lipophilicity and solubility, and higher Spearman correlations for clearance and half-life, compared with general LLM-based approaches. Spearman measures how well predicted rankings match true orderings – critical in early-stage triaging where relative ordering of compounds often matters more than exact values.
On TargetBench 1.0, an open benchmark for target identification, Insilico’s TargetPro, built on its PandaOmics platform, demonstrates superior retrieval of clinically validated targets among the top-ranked predictions, significantly outperforming general LLMs across multiple diseases.
Earlier this year, Insilico introduced TargetBench 1.0 and TargetPro to encourage transparent, reproducible evaluation of AI systems in biology. Science MMAI Gym extends that philosophy from target discovery into a comprehensive training and benchmarking environment covering chemistry, biology, and clinical reasoning.
Introducing Science MMAI Gym: Can We Teach Any LLM Drug Discovery?
Science MMAI Gym directly tackles the question: Can we take any LLM including those that initially fail most drug discovery tasks – and train it into a high-performing scientific engine?
The Gym is architected as a multi-stage training regime for any causal LM, including open-source models such as Qwen, Llama, Mistral and others, as well as customer-owned or proprietary models:
Medicinal chemistry reasoning: over 4 million optimization chains, 700+ medchem structural rules, and curated examples linking structural changes to ADMET and potency outcomes.
Organic synthesis reasoning: more than 100 million reactions and industrial organic chemistry synthesis descriptions, plus 3,000+ retrosynthesis templates and tags.
DMPK and toxicity: 100+ predictive models for pharmacokinetics and 200+ models for toxicity and off-target selectivity.
3D information: hundreds of thousands to millions of molecular dynamics (MD) trajectories, protein pockets, and docking/simulation outputs that ground the model’s reasoning in geometry and physics.
Models undergo multi-task SFT with task and domain-specific reasoning to learn diverse tasks simultaneously, followed by offline and online reinforcement learning to hone reasoning skills using experimental or high-quality data generated by validated reward models. For example, rewards that increase when molecules stay drug-like, retain the scaffold, and improve multiple properties at once, or when trial-outcome predictions align with experimental clinical results.
3. Data decontamination and robust benchmarking
An automated data decontamination system checks for overlap between training and test splits, removing leakage across all tasks, including retrosynthesis (where multi-step data that contained public test sets were excluded).
Each training cycle is evaluated against public and in-house out-of-distribution (OOD) benchmarks, including TDC, MuMO-Instruct, FGBench, USPTO and internal retrosynthesis, ADMET, MedChem datasets, TargetBench, and ClinBench.
In a typical engagement, a customer provides their base model. Over 1–3 months of “membership” at Science MMAI Gym, Insilico runs the full curriculum and returns an updated model with substantially improved performance, along with detailed benchmark reports and optional wet-lab validation.
Chemistry Superintelligence (CSI): Qwen3-14B Case Studies
A central CSI case study in the slide deck follows Qwen3-14B, an open-source causal LLM:
Before Science MMAI Gym
Qwen3-14B, used with five-shot in-context learning, fails completely on roughly 70% of medchem benchmarks, and performs poorly on many TDC ADMET tasks and retrosynthesis metrics. In several tasks, its errors are far beyond SOTA goals, and it scores near zero on single-step retrosynthesis quality as measured by Insilico’s ChemCensor metric, which assesses the plausibility and selectivity of proposed reactions on a 0–5 scale.
After two weeks at Science MMAI Gym
The Qwen3-14B-MMAI variant solves over 95% of medchem benchmarks and becomes a “single-model-does-it-all” chemistry engine:
Achieves SOTA or near-SOTA performance on 4 of 22 ADMET tasks in the TDC suite against task-specific specialist models, while beating TxGemma-27B-Predict – a strong category-specific generalist – on 12 of 22 tasks in a single SFT+RFT run.
Delivers SOTA Success Rate on 5 of 5 optimization tasks in the MuMO-Instruct benchmark, while maintaining high structural similarity (0.5–0.6) to the starting molecules, ensuring modifications remain realistic analogs rather than property-hacking artifacts.
Outperforms ether0, a reinforcement-learning-tuned domain generalist LLM but based on general reasoning as opposed to domain-specific, in single-step retrosynthesis on both standard USPTO-50k and out-of-distribution in-house expert datasets according to ChemCensor-based metrics.
Qualitatively, the “before and after” chat transcripts show that base models tend to generate vague, non-specific rationales and incorrect chemistry, whereas post-Gym models internalize domain reasoning: they parse SMILES and 3D information, decompose structures, explain ADMET liabilities, propose rational modifications, and even generate plausible 3D binding poses in the reasoning traces, often achieving SOTA without external tool calls.
Biology and Clinical Superintelligence (BSI): TargetBench and ClinBench
Science MMAI Gym for Biology builds on one of the largest integrated biology and clinical datasets assembled in the industry:
1.3M+ omics samples across ~1,000 diseases, including RNA-seq, microarrays, single-cell data, ATAC-seq, proteomics, GWAS/EWAS, and more.
7M+ gene–disease associations, manually curated and AI-aggregated.
47M+ scientific documents, including publications, patents, grants, and clinical trial records.
300K+ patients with longitudinal EHR data, including partially mortality-linked cohorts.
These data power multiple reasoning tasks: target identification, indication prioritization, trial outcome prediction, treatment response modeling, biomarkers for survival and therapy response, and aging biology, supported by PandaOmics scores, 700+ “golden projects,” Precious-GPT aging clocks, and TargetPro novel target scorers.
A base Qwen3-4B model begins with an F1 score of ~0.82 on predicting success vs failure of Phase 2 trials whose results were published after January 1, 2025.
After SFT and GRPO-based reinforcement training at MMAI Gym, the model’s F1 score rises to 0.94, with accuracy of 0.92 and recall of 1.00 – outperforming a broad set of frontier LLMs, including several widely used commercial models that cluster around F1 scores of 0.82–0.87 on the same benchmark. F1 balances precision and recall, making it a practical summary of overall classification quality for unbalanced clinical datasets.
2. TargetBench – Clinical Target Retrieval and Novel Target Quality
Starting from a weak baseline, Qwen3-1.7B fine-tuned with SFT and GRPO at MMAI Gym climbs to the top composite ranking for novel target identification across multiple diseases, outperforming frontier LLMs on multiple metrics such as the percentage of: novel targets with known protein structures, targets considered druggable, linked to approved drugs, average pathway relevance scores, number of available bioassays, and number of known gene modulators – all indicators of biological plausibility and translational readiness.
Together, these results suggest that Science MMAI Gym can turn a general LLM into a biology- and clinic-savvy copilot, capable of assisting with tasks like target triage, indication expansion, trial design, and biomarker discovery.
Towards Pharmaceutical Superintelligence (PSI)
The Pharmaceutical Superintelligence (PSI) vision described in the slide deck positions Science MMAI Gym as a continuous training environment:
LLMs are first evaluated through benchmarking across chemistry and biology tasks.
Molecular and biological datasets are curated and harmonized, and tasks and benchmarks are selected to reflect real research settings.
Models undergo multi-day MMAI Gym training sprints, combining multi-task SFT, reasoning-aware RL from AI feedback (RLAIF), and architecture selection.
Processed learnings feed into ongoing iterations, gradually building CSI and BSI pillars that together form PSI – a model (or model family) capable of supporting end-to-end drug discovery and development workflows.
Partners can move from a generic baseline LLM to a PSI-tuned model stack adapted to their proprietary data and R&D strategies, with optional wet-lab validation through Insilico’s automated assay platforms.
Business Model: “Membership” in the AI GYM for Science
Science MMAI Gym is offered as a membership-style program:
Flexible terms – from intensive two-week or one-month sprints to three-month or longer PSI-oriented engagements.
One-time or recurring subscriptions, where Insilico runs end-to-end training, benchmarking, and validation cycles, tailored to the partner’s priorities (chemistry-centric CSI, biology/clinical-centric BSI, or full PSI).
At the end of a membership cycle, partners receive a significantly upgraded model – a CSI/BSI/PSI-enhanced version of their original LLM with materially improved performance on internal and external benchmarks. Additionally they receive detailed benchmark reports covering public suites (e.g., TDC, MuMO-Instruct, FGBench, TargetBench, ClinBench, USPTO-50k) and, where appropriate, out-of-distribution in-house benchmarks.Optional wet-lab validation packages where model-generated hypotheses (e.g., novel targets or optimized molecules) are tested in Insilico’s experimental platforms are also included.
The overarching promise is “up to 10x performance improvement compared to baseline”, and substantial gains even relative to specialist models on multiple tasks – translating to more reliable toxicity predictions, better target triage, and more accurate trial outcome forecasts.
Insilico invites pharma and biotech companies, AI labs, and cloud providers to “bring your AI model to Science MMAI Gym” and explore CSI, BSI, and PSI memberships tailored to their R&D pipelines.
Forward-Looking Statements:
This press release contains forward-looking statements relating to the likely future developments in the business of the Company and its subsidiaries, such as expected future events, business prospects or financial performance. The words “expect”, “anticipate”, “continue”, “estimate”, “objective”, “ongoing”, “may”, “will”, “project”, “should”, “believe”, “plans”, “intends”, “visions”, “schedule” and similar expressions are intended to identify such forward-looking statements. These statements are based on assumptions and analyses made by the Company at the time of this press release in light of its experience and its perception of historical trends, current conditions and expected future developments, as well as other factors that the Company currently believes are appropriate under the circumstances. However, whether actual results and developments will meet the current expectations and predictions of the Company is uncertain. Actual results, performance and financial condition may differ materially from the Company’s expectations.
All of the forward-looking statements made in this press release are qualified by these statements. Consequently, the inclusion of forward-looking statements in this press release should not be regarded as representations by the Board or the Company that the plans and objectives will be achieved, and investors should not place undue reliance on such statements.
The Company, its Board, the employees and the agents of the Company assume (a) no obligation to correct or update the forward-looking statements contained in this press release; and (b) no liability for any losses in the event that any of the forward-looking statements do not materialise or turn out to be incorrect.
About Insilico Medicine
Insilico Medicine is a pioneering global biotechnology company dedicated to integrating artificial intelligence and automation technologies to accelerate drug discovery, drive innovation in the life sciences, and extend health longevity to people on the planet. The company was listed on the Main Board of the Hong Kong Stock Exchange on December 30, 2025, under the stock code 03696.HK.
By integrating AI and automation technologies and deep in-house drug discovery capabilities, Insilico is delivering innovative drug solutions for unmet needs including fibrosis, oncology, immunology, pain, and obesity and metabolic disorders. Additionally, Insilico extends the reach of Pharma.AI across diverse industries, such as advanced materials, agriculture, nutritional products and veterinary medicine. For more information, please visitwww.insilico.com