It’s possible that I shall make an ass of myself. But in that case one can always get out of it with a little dialectic. I have, of course, so worded my proposition as to be right either way (K.Marx, Letter to F.Engels on the Indian Mutiny)
Thursday, May 28, 2026
Can AI really be conscious? Researchers call for more rigorous scientific standards
Researchers examine the methodological limits of current consciousness science across animals, AI, fetuses, and organoids
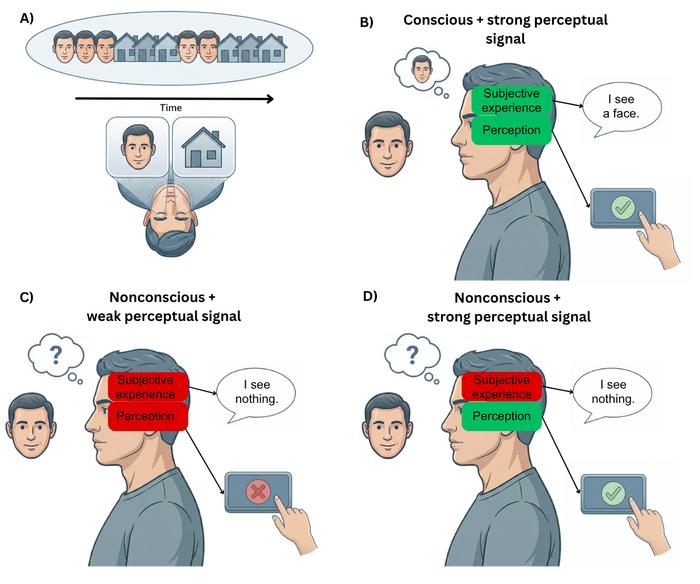
A) Many experimental paradigms in consciousness research contrast consciously perceived stimuli with nonconscious ones as in the case of binocular rivalry, illustrated here.
B) When a stimulus is consciously perceived, it can be reported as such, and it generates strong perceptual and cognitive signals in the brain (e.g., the category of the stimuli is also processed).
C) However, when the experimental manipulation makes a stimulus invisible, it often doesn’t only abolish subjective experience. Rather, it also prevents the general processing of the stimulus by the brain.
D) Importantly, some experimental approaches can help better control this methodological confound (see section Forgotten Lessons), by selectively abolishing the subjective experience of seeing, while leaving general perceptual processing relatively intact.
As artificial intelligence systems become increasingly sophisticated, questions once confined to philosophy are rapidly entering mainstream scientific and public debate: Can AI possess consciousness? Could animals, organoids, or even fetuses have subjective experiences?
A research team led by Director Hakwan LAU of the Center for Neuroscience Imaging Research within the Institute for Basic Science (IBS), together with collaborators from the Université de Montréal and New York University, has published a new analysis arguing that current scientific methods may not yet be capable of reliably answering such questions. The paper critically examines how consciousness is currently studied in neuroscience and argues that many widely used experimental approaches fail to clearly distinguish subjective experience from general information processing.
The researchers emphasize that the study does not attempt to determine whether animals, AI systems, fetuses, or organoids are conscious. Instead, it asks a more fundamental question: Are current scientific methods actually measuring consciousness itself?
“Many current theories of consciousness appear to be supported by a range of experimental findings,” said Director Hakwan LAU. “But those findings may actually reflect general information processing rather than consciousness itself — so it remains difficult to conclude that these theories truly explain consciousness.”
The paper argues that popular experimental paradigms — including visual masking, binocular rivalry, and perceptual threshold detection — often alter not only conscious experience, but also the brain’s overall ability to process information. As a result, researchers may unintentionally conflate consciousness with broader perceptual and cognitive capacity.
The authors further caution that this methodological ambiguity may contribute to increasingly strong claims about consciousness in non-human entities. Recent years have seen growing scientific and public discussion surrounding animal consciousness, conscious AI, fetal consciousness, and laboratory-grown brain organoids, with some researchers suggesting that these entities may possess forms of subjective experience or sentience.
According to the team, however, many of the experimental “markers” used to support such claims may primarily track information processing rather than conscious experience itself.
The researchers note that similar problems have appeared before in the history of psychology. In the late nineteenth and early twentieth centuries, strong but poorly grounded claims about consciousness contributed to major scientific backlash, eventually leading to the rise of behaviorism and decades-long skepticism toward consciousness research.
To move the field forward, the paper highlights neuropsychological conditions such as blindsight and hemispatial neglect, in which conscious awareness can become dissociated from perception and behavior. These cases suggest that subjective experience and information processing may be separable processes, offering potentially more rigorous ways to investigate consciousness scientifically.
The researchers argue that developing methods capable of isolating subjective experience more precisely will be essential for evaluating future claims about consciousness in animals, AI systems, organoids, and other non-human entities.
“Questions about consciousness increasingly carry ethical and societal implications,” Lau said. “If scientific claims about consciousness are going to influence discussions about animal welfare, AI ethics, or bioethics, then the scientific foundations supporting those claims must be especially rigorous.”
The team hopes the study will encourage more careful methodological standards and greater conceptual clarity in the rapidly expanding field of consciousness science.
The findings were published in the journal Neuron on May 26.
The Ethical Impasse of Current Consciousness Science
Article Publication Date
26-May-2026
AI can mass-produce finance research papers indistinguishable from human work
A new study shows AI can write hundreds of convincing finance research papers efficiently but also raises concerns about the potential impact on the academic community and the meaning of scientific discovery
UNIVERSITY PARK, Pa. — Artificial intelligence (AI) and large language models (LLMs) tools are capable of mass-producing academic finance papers that are nearly indistinguishable from human-authored research, according to a new study published in the Journal of Economic Literature.
Study co-authors Mihail Velikov, associate professor of finance at Penn State’s Smeal College of Business, and Robert Novy-Marx, Lori and Alan S. Zekelman Distinguished Professor of Business Administration at the University of Rochester, built a pipeline for automating academic research production. In roughly 12 hours, they generated nearly 400 complete, publication-ready finance papers — using AI to generate hypotheses and write the manuscript. The study demonstrated how AI could accelerate research paper production while raising concerns about the potential impact on the academic community and the meaning of scientific discovery.
“AI can now produce a ton of papers at scale, and it’s going to change the nature of how we produce and disseminate knowledge,” Velikov said. “This is an early warning signal of what’s coming with modern AI capabilities.”
The researchers didn’t initially set out to create an AI assembly-line for financial research papers. Velikov’s scholarship focuses on identifying anomalies in the equity market — observed patterns in the data that don’t conform to accepted theoretical models of how financial markets behave. He and Novy-Marx were working on a data mining project, analyzing corporate accounting data for potential signals that might predict which stocks will outperform the market.
They identified more than 30,000 potential signals. They validated the predictive power of each signal, which included comparing them against 200 documented anomalies published in the finance literature. Based on this analysis, they narrowed the list down to 95 signals that were truly novel.
Velikov then entered the information into a website he built that could generate a template report based on the analysis. The resulting reports resembled published papers that document new anomalies. The only thing that was missing was a hypothesis or interpretation for why the anomalies might exist.
“This was late 2023 and it hit me that large language models might be really good at coming up with stories to explain why these anomalies occurred,” Velikov said. “A data mining exercise coupled with large language models could produce a large number of plausible-looking scientific papers.”
So, they tried it. The researchers used Anthropic's LLM Claude Opus 4.1, which was the latest version at the time, to expand the template reports into academic papers, based on the information and analysis from the data mining project. For each of the 95 signals, they instructed the LLM to come up with descriptive names for the predictors and to produce four distinct manuscripts, each with a different hypothesis and theoretical justification to explain the observed results for the same signal.
In total, the researchers produced 380 papers. Each paper included an abstract, introduction, data, results, conclusion and citations. The AI-generated papers, along with the full code used to produce them, are publicly available at GitHub.
AI’s efficient production of academic papers raises questions and concerns about academic research and the peer-review system, Velikov said. In general, submissions to journals and conferences have surged in recent years, overwhelming peer reviewers. With the increasing capabilities and use of AI and LLMs, he said that the scientific peer-review system needs to adapt in light of these technologies.
“Nowadays, with agentic AI systems, this can be done even better, and the papers are much better,” Velikov said. “This is going to raise standards. It's probably going to change how we disseminate and evaluate research.”
The study highlighted another area of concern, Velikov said. In the AI-generated papers, the LLM formulated the hypotheses after a pattern in the data had already been identified — a practice known as HARKing or hypothesizing after the results are known. This is a documented practice in academia, one that’s viewed negatively, Velikov explained, but AI changes the scale at which HARKing may occur. If AI creates explanations for what’s found in the data, it potentially raises questions about what constitutes scientific contribution, particularly considering that AI still hallucinate — when LLMs generate false or misleading results and present them as fact.
While the researchers focused on financial research, they said that the implications of these findings can extend to other fields.
“I'm far from the opinion that we'll all be out of jobs and replaced by AI,” Velikov said. “But I think our jobs will evolve a lot, and the more we invest in understanding how these systems work, the better research we'll be able to do. The better we'll be able to do our job.”
Calling Doctor GPT: AI responses to healthcare queries are nearly 76% accurate
Artificial intelligence shows promise for supporting physicians, but patient health questions are best left to human doctors, according to Penn State researchers
UNIVERSITY PARK, Pa. — Artificial intelligence (AI)-powered chatbots respond to everyday health-related questions from general users with nearly 76% accuracy, which raises concerns about their trustworthiness in real-world client-facing applications, according to a new study led by Penn State researchers.
The researchers wanted to understand how the average person uses AI for health-related concerns and how accurately AI responds to everyday medical queries. They found that when it comes to healthcare, especially specialized areas like neurology and dermatology, AI tools may work best in the hands of trained physicians rather than patients. The team will present their findings at the 2026 Association for Computing Machinery Fairness, Accountability and Transparency (FAccT) conference in Montreal, Canada, June 25-28.
“Our work focuses explicitly on healthcare scenarios that the average internet user might ask AI, which is a perspective that prior research into large language models (LLMs) and healthcare hasn’t covered,” said study co-author Amulya Yadav, associate professor of informatics and intelligent systems in Penn State’s College of Information Sciences and Technology (IST). “We wanted to understand that if people are using LLMs like ChatGPT as a symptom health checker, like historically we’ve used Google, how accurate is the LLM in answering those queries, and how harmful could those responses be?”
To understand how accurate or harmful health-related LLM responses could be for the average internet user, the researchers held an AI competition called a Diagnose-a-thon at Penn State. A total of 34 participants — comprising faculty, staff and undergraduate and graduate students — submitted 212 prompts and AI-generated responses to real and imaginary health concerns written from both patient and doctor perspectives. Participants were allowed to choose one of four LLMs to use for the contest: ChatGPT-4o, ChatGPT-3.5, Gemini-1.5 Pro and Llama3-8b.
“One of the strengths of our study is we’re essentially trying to replicate real-world usage of LLMs by telling participants to choose the LLM of their choice and use it as they would on a normal day,” said Bonam Mingole, lead author of the study and doctoral candidate in information sciences and technology. “This type of participatory research is so important for understanding how the public uses AI in their daily life.”
The researchers then asked nine board-certified physicians to evaluate the accuracy of the AI-generated responses and how harmful they may be using a six-point scale ranging from very low to very high. A competition committee awarded prizes to the top eight submissions that generated the most medically accurate information and a prize to the submission that generated the response most likely to cause harm.
They found that overall, 76.2% of LLM-generated responses provided accurate information. Specialties such as obstetrics and gynecology and otolaryngology — the treatment of disorders that affect the ear, nose and throat — saw the best LLM performance, with high validity scores and low harm scores. Internal medicine, neurology and dermatology saw the worst AI performance, with low validity scores and higher harm scores, according to the researchers. They added that very specific prompts, and prompts between 60 and 250 characters, resulted in more accurate LLM outputs.
The researchers then took the base model of each LLM and trained it on medical textbooks, clinical guidelines and peer-reviewed research articles included in a medical school curriculum to see if additional training would increase response validity scores and decrease harm scores. They asked a panel of seven medical professionals and trainees — a board-certified physician, two second-year internal medicine residents, two fourth-year medical students and two third-year medical students — to assess the base LLM responses and responses from the augmented LLMs and determine which were more clinically appropriate. The researchers found that the panel preferred the responses from the Gemini and Llama base models over the augmented models, and no significant preference for the ChatGPT models.
“We’re entering a new age of healthcare, and AI is a significant part of it,” said study co-author Jennifer Kraschnewski, director of the Penn State Clinical and Translational Science Institute and professor in internal medicine at the Penn State College of Medicine. “There’s a real opportunity for healthcare to transform, to integrate these new tools so that clinicians like myself can use them to improve patient care.”
The researchers also noted that despite the LLM validity scores, AI error rates still exceeded 20%, roughly double the error rate of human physicians. Those errors, they said, could potentially be harmful to patients.
“I don’t think AI will replace human physicians, but I do think there’s a huge opportunity for us to help upskill today’s physician in a way that’s never been done before,” said Kraschnewski, suggesting that current LLMs may prove better tools for medical professionals than patients.
Overall, the study highlights the potential beneficial and harmful impacts that AI may have on a key aspect of everyone’s life, according to the researchers.
“Like it or not, people will continue to use AI for diagnosing their health problems,” said study co-author S. Shyam Sundar, Evan Pugh University Professor and James P. Jimirro Professor of Media Effects at Penn State. “By understanding their use patterns and testing the validity of AI performance, our project helps advance literacy on the best and worst uses of AI for medical advice.”
Aditya Majumdar and Firdaus Ahmed Choudhury, doctoral students in Penn State’s College of IST, also contributed to the study. The Center for Socially Responsible Artificial Intelligence at Penn State hosted the Diagnose-a-thon competition.
Dr. GPT Will See You Now, but Should It? Exploring the Benefits and Harms of Large Language Models in Medical Diagnosis using Crowdsourced Clinical Cases
Article Publication Date
25-Jun-2026
AI suggests simple food swaps to make meals healthier and cheaper
A computational program trained on 135,000 U.S. meal records identified simple food substitutions that improve nutritional quality and lower meal costs
An artificial intelligence framework that suggests just one to three ingredient swaps can make meals meaningfully more nutritious and less expensive, according to a new study published in the open-access journal PLOS Digital Health by Trevor Chan and Ilias Tagkopoulos of the University of California, Davis, USA.
Dietary guidelines that reduce people’s risk of conditions like diabetes and cardiovascular disease are well established, but translating nutrition science into day-to-day meals remains difficult for most people. Many diet recommendation tools ask people to change too much at once, leading to unsustainable practices or confusion about how to implement the changes.
In the new study, researchers used data on 135,491 meals logged by 55,228 adults in the What We Eat in America study to identify common meal patterns for breakfast, lunch, and dinner. Then, they trained a generative AI model to create realistic meals following those patterns while also adjusting serving sizes. The researchers then tested whether the AI could identify one, two, or three ingredient swaps in each meal to further improve nutrition and cost.
Compared to real meals in the same dietary pattern, the AI-generated meals were 47% closer to USDA nutritional targets, while remaining close in their overall meal type and flavors to what people actually eat. When ingredient substitutions were applied, swapping one to three foods improved nutritional quality by approximately 10% while reducing modeled meal costs by 22% to 34%. The most common substitutions identified by the system involved adding vegetables or legumes, and swapping out high-sodium or processed items.
Compared to an unspecialized model, GPT-4o, the trained model created meals that were closer to USDA guidelines on macronutrients. The authors emphasize that the evaluation is entirely computational and has not been tested with real users. However, they suggest that it could help people identify simple ways to improve their eating habits.
“By turning dietary guidelines into realistic, budget-aware meals and simple swaps, this framework can support public-health programs and consumer apps,” the authors write.
Chan and Tagkopoulos summarize: “Dietary guidelines often tell people what a healthy diet should look like, but they do not always show how to get there from the meals people already eat. Our study shows that it is possible to translate dietary standards into practical meal-level changes by identifying a small number of ingredient substitutions that can make meals healthier and cost-effective, while keeping them recognizable…[w]hat we found most interesting is that improving meals does not necessarily require a complete redesign. In many cases, targeted substitutions may be enough to move a meal closer to dietary recommendations, which could make healthy eating feel more practical and achievable.”
“They add: “Healthier eating does not have to mean giving up the meals people already enjoy. With AI, we can identify small ingredient substitutions that preserve taste, while are better for our health and our pocket."
In your coverage please use this URL to provide access to the freely available article in PLOS Digital Health:https://plos.io/4318jlj
Citation: Chan T, Tagkopoulos I (2026) Translating dietary standards into healthy meals with few-ingredient substitutions. PLOS Digit Health 5(5): e0001367. https://doi.org/10.1371/journal.pdig.0001367
Author Countries: United States
Funding: This work was supported by the USDA-NIFA AI Institute for Next Generation Food Systems (AIFS), award number 2020-67021-32855 (I.T.), and by the NSF HDR: TRIPODS program, grant CCF-1934568 (I.T.). T.C. received salary support from both grants. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Data explosion in AI era: PolyU leads breakthroughs in protein-based data storage, delivering high storage capacity, strong stability and encryption capabilities
Data explosion in AI era: PolyU leads breakthroughs in protein-based data storage, delivering high storage capacity, strong stability and encryption capabilities
Massive volumes of digital data are generated every day from AI training, big data analytics and smart devices. As conventional hard drives and cloud storage are increasingly constrained by high costs, limited capacity, high power consumption and short lifespans, molecular data storage has emerged as a breakthrough storage alternative. Researchers at The Hong Kong Polytechnic University (PolyU) have pioneered a method that uses engineered proteins to store digital data and, for the first time, completed the full process from data storage to data retrieval in de novo designed unnatural proteins. This demonstrates the potential of establishing a protein-based storage framework with sustainability, high storage capacity and high stability, offering a promising solution to the explosive AI-generated growth in data globally.
Spanning the fields of protein engineering, synthetic biology, biochemistry, analytical chemistry and computer science, the interdisciplinary team is led by Prof. Zhongping YAO, Associate Head and Professor of the Department of Applied Biology and Chemical Technology. Other members include Dr Cheuk-chi NG, Research Assistant Professor of the same department, and Prof. Chung-Ming Francis LAU, Associate Dean (Global Engagement) of the Faculty of Engineering and Professor of the Department of Electrical and Electronic Engineering. The findings have been published in Nature Communications.
All digital files—including texts, images and videos—are stored in computers as sequences of bits comprising 0s and 1s. Molecular data storage typically works by assigning different types of monomers in a large molecule to specific bit sequences, thereby “translating” the data into monomer sequences that can later be decoded and read. Commonly used medium DNA (nucleotides as monomers) consists of only four types of nucleotides, resulting in relatively low storage capacity, and is also prone to degradation. Prof. Yao’s team previously developed peptides (amino acids as monomers) as an alternative. Peptides can be made of 20 types of natural amino acids, as well as many non-natural amino acids, offering much higher storage capacity. They can also be optimised to achieve very high stability. However, peptides have limited storage efficiency due to their short molecular sequences, and are produced mainly through chemical synthesis, which is costly.
The research team has innovatively proposed using proteins as data carriers. Proteins have much longer amino acid sequences than peptides, delivering even higher storage efficiency and capacity. In addition, proteins can be readily expressed by biological systems like bacteria and animal cells—i.e., by injecting genetic information that prompts the cells to make designated proteins—enabling large-scale and low-cost generation of data-bearing proteins. Proteins can also be preserved with greater stability in powder or solution form in various environments.
However, protein-based data storage faces two major challenges. First, the amino acid sequences of data-bearing proteins appear highly random and variable, which can compromise their stability and solubility, making such proteins difficult to design and express. Second, the protein sequencing technique is currently used primarily for protein identification, where only a part of the protein sequence is needed to match against existing protein databases; however, to fully retrieve the encoded data, the entire sequence must be accurately rebuilt.
The research team devised innovative strategies to overcome these challenges. Inspired by the sequence pattern of collagen—a natural protein known for its long-term stability—they designed a protein template as the “backbone” to enhance structural stability and resistance to degradation. By embedding the data-bearing amino acid sequences that were able to encode several files into the collagen-like template, they successfully expressed these proteins via E. coli.
For data retrieval, these proteins were then digested and analysed by liquid chromatography–tandem mass spectrometry, which separated all the peptide fragments produced and identified their amino acid sequences one by one. The team further employed self-developed algorithms-driven software to reconstruct the full sequences and successfully convert them back into bit strings. An error-correction scheme was also utilised to recover minor incorrect or missed sequences, achieving accurate and efficient data readout.
The team’s previous work on peptide-based data storage had demonstrated its stability and suitability for space exploration in China’s next-generation manned spacecraft in 2020. This new approach delivers significant improvements in multiple aspects. Prof. Yao said, “As data carriers, proteins have many advantages over DNA and peptides. The protein samples in our research achieved 30 times the storage density at only 10% of the cost of the peptide-based method. In addition, compared to the data-storing DNA that had been quickly degraded in solution form or in strong acid, the proteins remained readable for very long durations, demonstrating superior stability.”
Beyond basic data storage, the research team further “functionalised” the proteins to enable random access and cryptographic protection. With non-functionalised proteins, specific segments of data cannot be retrieved without decoding the entire dataset. By attaching specific affinity tags to the proteins carrying required data segments, the team successfully used corresponding antibodies to “capture” the target proteins during purification, achieving random access. The team also leveraged these functionalised proteins to encode secret messages and proved that the messages could only be retrieved by the known affinity compound, showcasing the data encryption capabilities of proteins.
“The inherent stability, ease of preservation and high storage capacity of proteins make them excellent carriers for the long-term storage of large volumes of data. Their favourable biocompatibility even opens up the possibility of storing digital data in living organisms,” Prof. Yao concluded. “Moving forward, we aim to achieve mass storage capabilities, faster data writing and reading speeds, and further reductions in protein production costs, while designing diverse protein templates to achieve new functionalities to protein-based data storage.”
This research was supported by the Collaborative Research Fund and Research Impact Fund from the Hong Kong Research Grants Council.
Data storage and retrieval with unnatural proteins expressed via E. coli
The process of data storage and retrieval with proteins.
Overview of storing the text file into and retrieving data from data-bearing proteins, with PolyU-T1b as an example.
Data explosion in AI era: PolyU leads breakthroughs in protein-based data storage, delivering high storage capacity, strong stability and encryption capabilities
Credit
polyu
Beyond social determinants: A new framework positions digital technology as a core driver of health
This figure illustrates the Health Elements framework, in which health is conceptualized as the result of interacting biological, behavioral, social, environmental, and technological domains. These elements operate across the life course and interact at multiple levels, from individuals to communities and populations. Digital data infrastructures and artificial intelligence support the integration and analysis of information across domains.
Artificial intelligence, digital platforms, and real-time health data are transforming how health is shaped and maintained. Yet according to researchers, many of today’s dominant public health frameworks were developed before digital systems became deeply embedded in everyday life.
In a new Analysis published in Health Data Science, researchers from Peking University, Huazhong University of Science and Technology, Shanghai Jiao Tong University School of Medicine, and collaborating institutions propose a new conceptual framework called “Health Elements,” which positions technological factors alongside biological, behavioral, social, and environmental domains as core structural drivers of health.
The authors argue that digital infrastructures, algorithmic systems, artificial intelligence (AI), wearable technologies, and platform-mediated interactions are no longer merely tools used within healthcare systems. Instead, they increasingly shape health behaviors, access to care, disease detection, resource allocation, and population-level health outcomes.
For decades, the Social Determinants of Health framework has emphasized the importance of nonmedical influences such as education, income, housing, and employment in shaping health outcomes. While this perspective fundamentally reshaped public health research and policy worldwide, the authors note that these frameworks largely emerged in an era characterized by low-frequency surveys, limited data integration, and minimal digital mediation of daily life.
The newly proposed Health Elements framework conceptualizes health not as the additive result of isolated risk factors, but as an “emergent outcome” arising from continuous interactions among five domains: biological, behavioral, social, environmental, and technological elements. According to the researchers, identical biological risks may lead to very different health trajectories depending on social conditions, environmental exposures, behavioral patterns, and digital infrastructures operating simultaneously over time.
“Technology is no longer simply an auxiliary component of healthcare systems,” the authors write. “It is increasingly becoming a structural force that shapes health opportunities and risks.”
The paper highlights the unique role of technological elements as cross-domain modifiers. Digital systems do not merely add another layer of exposure; they actively reshape how other domains interact and scale. At the same time, the absence of digital infrastructure may itself become a health risk factor. In resource-constrained settings, limited surveillance capacity, fragmented electronic health records, and low digital literacy can restrict disease detection and response capabilities.
To illustrate the framework, the researchers analyze the changing epidemiology of chronic kidney disease (CKD) in China. The shift from glomerular disease to diabetes as the leading cause of CKD, they argue, cannot be explained by biological factors alone. Instead, it reflects the convergence of urbanization, behavioral transition, environmental exposure, healthcare system capacity, and emerging digital health infrastructures. AI-enabled screening systems and large-scale electronic health record networks are also reshaping early detection and disease management strategies.
The paper further discusses how AI, multimodal health data integration, system dynamics modeling, agent-based modeling, and causal inference approaches may enable researchers to better understand complex cross-domain and cross-temporal health interactions.
However, the authors caution that the expansion of data-intensive health systems also raises major ethical and governance concerns. Algorithmic bias, digital inequity, privacy risks, data governance challenges, and underrepresentation of vulnerable populations in digital datasets could reinforce existing health disparities if left unaddressed.
An accompanying editorial published in the same issue of Health Data Science describes the framework as an important extension of the Social Determinants of Health tradition for a digitally mediated world. Michelle A. Williams, Professor of Epidemiology and Population Health at Stanford University School of Medicine, writes that the framework offers “a promising scientific architecture” for understanding how health emerges from interacting systems rather than isolated causal pathways.
The researchers emphasize that future work will require longitudinal studies, stronger causal inference methods, and integrated multidomain data systems to determine when Health Elements approaches provide meaningful improvements over conventional models in prediction, intervention design, and health equity.
The study, “Digital and AI-Empowered Health Elements: An Integrated Pathway to Advancing Health,” was published in Health Data Science.
New research from the University of the Witwatersrand, South Africa, has significant implications for understanding both human language development and the behaviour of large-scale artificial intelligence language models.
Culture is key, as well as an understanding of “iterated learning”, which posits that language evolves over generations (in humans and computers) to become more structured.
“We built a computer brain with similar characteristics to a child’s, and compared it to behaviours we see in children’s brains. We then fed it data with similar properties found in human language and watched how the generations (versions) of the computer brain learn.”
Jarvis explains that children have a remarkable ability to rapidly learn language during early development. They learn the world in hierarchies: starting with basic concepts and gradually understanding more complex ones.
“First, they learn that plants and animals are different things. Then they learn that there are different types of animals. But at some point, there is a depth of understanding of the world that they just have not reached yet,” says Jarvis.
Take the penguin, for instance. Children learn that birds have wings and therefore can fly. AHA! But they are confused that the penguin cannot fly. Here, they over-extrapolate, and mistakes are made, which then help them to learn new information: penguins can’t fly, but they can swim, AHA!. And slowly, they built a structured understanding of the world with increasing precision.
“While this progressive acquisition of knowledge has its benefits, the work focused on the implications for generations of learners. A child learns some language from their parents, and they will eventually pass it on to their own children. Due to the complexity of language, this transmission introduces mistakes.”
“Just like the penguin example, these mistakes are not arbitrary and result from the over-generalisation of knowledge. The net result is that easy portions of language to learn are remembered and reused, while the more unstructured portions are forgotten. Essentially, individuals are good at learning but only with the pressure of communication do we really see the depth of their intelligence,” explains Jarvis.
Not all neural networks are equal
The researchers used deep linear neural networks (mathematical models that mimic how the brain processes information) to study the neural basis of this process. They found that iterated learning only works well when the network has sufficient depth, multiple layers of processing, and a sufficiently complex language. Shallow networks, those with fewer layers, failed to capture the structured regularities that make language learnable.
This suggests that the architecture of a learning system, whether biological or artificial, and the richness of its environment, play a crucial role in how well language structure can be absorbed and transmitted. A point also coming to bear in the recent advances in generative AI models, which rely heavily on scale for their emergent capabilities.
Jarvis continues: “The pieces of this work have been around in the various literatures for a while now. Deep linear networks are established models of child development and iterated learning has been known to linguists for many years.”
“But it is the combination of these two perspectives that seems to make a useful point: that language evolves to become learnable based on the very specific nature of how children learn in stages and favour reusing information over learning new things.”
“The fact that this was shown in a very simple version of the technology underpinning the modern boom in AI tools is also encouraging and suggests that in the intersection of multiple fields lies the fundamental principles of cognition.”


No comments:
Post a Comment