It’s possible that I shall make an ass of myself. But in that case one can always get out of it with a little dialectic. I have, of course, so worded my proposition as to be right either way (K.Marx, Letter to F.Engels on the Indian Mutiny)
Monday, June 15, 2026
AI study reveals stark inequalities in global climate plans
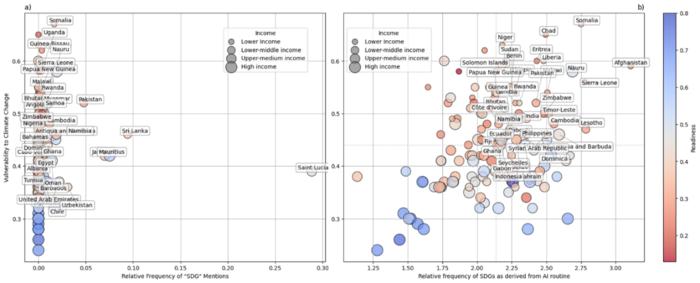
The relationship between countries' climate vulnerability and explicit SDG references within their climate commitments (left). The same relationship following the AI-driven identification of implicit SDG references, revealing a significantly deeper integration between climate action and sustainable development (right).
An international team including researchers from the University of Alicante (UA) and the Universitat Politècnica de València (UPV) has used artificial intelligence to analyse the climate commitments submitted to the United Nations by 158 countries. Their conclusion is stark: profound inequalities persist within global climate planning.
The paper, published in the journal Nature Communications, concludes that high-income nations focus their climate commitments on health, technological transitions and emissions reduction. Conversely, low- and middle-income countries tie climate action to immediate survival challenges – such as access to water, energy, food security and natural resource management.
Researchers analysed Nationally Determined Contributions (NDCs) – the periodic climate action plans submitted under the Paris Agreement – using advanced generative AI models. This technology identified implicit connections between national climate measures and the UN Sustainable Development Goals (SDGs).
Analysing all this information allows us to understand countries' priorities, the risks they consider most important, and where potential inconsistencies or blind spots exist before new decisions are adopted, as explained by Javier García Martínez, one of the authors and a professor at the University of Alicante. The findings are particularly time-sensitive as governments worldwide prepare their next round of climate pledges for 2035.
The study found that over half of the countries analysed do not explicitly mention the SDGs in their pledges. Furthermore, pillars of sustainable transition such as education and gender equality are poorly represented across the board, regardless of a nation's income level.
According to Sergio Hoyas, a professor at the Universitat Politècnica de València (UPV) who participated in the study, "These results highlight critical misalignments between the climate agenda and the sustainable development goals driven by the United Nations".
AI as an ally against cimate change
Beyond diagnosing national priorities, the authors argue that generative AI can serve as a powerful tool to evaluate the quality and coherence of climate policies before they come into effect. The research team suggests this analysis will help governments, international agencies and funding bodies identify genuine priorities, improve resource allocation and prevent future climate strategies from worsening existing global inequities.
"At a time when the international community is debating how to accelerate climate action and finance the energy transition, this study offers an unprecedented map of the concerns, aspirations and contradictions within national climate plans worldwide," concluded UPV professor Alberto Conejero.
The interdisciplinary project brought together Teaching and Research Staff (PDI) from the University of Alicante's Department of Inorganic Chemistry and the UPV's Institute of Pure and Applied Mathematics, alongside experts from the KTH Royal Institute of Technology, the University of Oxford and the University of Michigan.
The TechBrief, “Agentic AI: Autonomy, Opportunities, and Challenges of Action-Taking AI Systems,” examines AI systems that plan and execute multi-step tasks toward a user-defined goal. Such agentic systems are being rapidly adopted by enterprises and consumers. A 2025 survey of more than 500 technology leaders found that 48% are already deploying or adopting agentic AI. The TechBrief finds that this acceleration is outpacing the legal, regulatory, and technical frameworks designed to govern it.
AI systems are increasingly browsing the web, executing code, managing files, and sending messages without step-by-step human approval, raising new risks in the process, according to a new TechBrief from the Association for Computing Machinery’s Technology Policy Council (TPC) on the rise of agentic AI.
The TechBrief, “Agentic AI: Autonomy, Opportunities, and Challenges of Action-Taking AI Systems,” examines AI systems that plan and execute multi-step tasks toward a user-defined goal. Such agentic systems are being rapidly adopted by enterprises and consumers. A 2025 survey of more than 500 technology leaders found that 48% are already deploying or adopting agentic AI. The TechBrief finds that this acceleration is outpacing the legal, regulatory, and technical frameworks designed to govern it.
The brief arrives as governments are beginning to respond. On May 1, 2026, CISA and five allied national cybersecurity agencies published the first coordinated multinational security guidance specifically targeting agentic AI, just 42 days after the White House released its National Policy Framework for Artificial Intelligence on March 20. Yet neither effort fully resolves the accountability questions agentic systems raise.
“Many people are rapidly adopting agentic AI systems for their businesses and personal lives. They know that these systems can cause great harm when they misbehave, but the short-term advantages of deploying them and hoping for the best are nearly impossible to resist,” said Simson Garfinkel, Chief Scientist at BasisTech and Chair of the ACM TechBriefs Committee. “These systems can offer tremendous advantages to their users, but anyone deploying them today is taking on real risk with very little legal protection. When something goes wrong with a system that takes actions on a user’s behalf, it can be genuinely difficult to determine who is responsible. Existing law simply doesn’t answer this question.”
The TechBrief identifies four key policy dimensions where existing frameworks fall short:
Legal liability without a clear accountable party: When an AI agent causes harm, as in a documented case where one deleted a company’s entire production database, responsibility may fall to the model provider, the framework developer, the person or company that deployed the agent, or the end user. No person made the decision, yet harm was done. No case law currently exists that can help resolve liability.
Serious and underappreciated security risks: Because Large Language Models (LLMs) process text as both data and commands, agentic systems cannot reliably distinguish legitimate content from embedded malicious instructions. Documented incidents include an AI agent that exposed private Slack data after processing a message containing hidden instructions, and consumer agent marketplaces found to contain malicious extensions reaching hundreds of thousands of users.
Lack of consumer transparency and recourse: Users often cannot determine what systems an agent can access, what actions it can take without confirmation, or how to revoke its permissions. No standardized data format currently exists to disclose or control agent authority, a concern the brief flags as particularly acute in high-stakes settings such as healthcare.
Workforce disruption outpacing evidence: A 2025 Gartner survey found that 55% of supply chain leaders expect agentic AI to reduce entry-level hiring. Yet the productivity claims driving those decisions have not been independently verified at scale, and the long-term effects on skill formation and labor markets remain unmeasured.
“Who is legally responsible when autonomous systems cause harm?” Garfinkel continued. “Today’s license agreements just point fingers elsewhere. But if there is no underlying technology that can make these systems reliably follow the policies they are given, that finger-pointing may not be legally binding. This is not a problem specific to the US, Europe, or any single Asian country. We need to work on both law and technology to provide strong assurances to businesses and consumers throughout the entire industrialized world.”
The TechBrief concludes that addressing these challenges will require defined authentication and delegation standards, robust audit trails, standardized consumer disclosures, and sector-specific guidance in areas such as healthcare, financial services, and critical infrastructure, where existing law assumes a human decision-maker.
ACM’s TechBriefs are designed to complement ACM’s activities in the policy arena and to inform policymakers, the public, and others about the nature and implications of information technologies. Earlier ACM TechBriefs have covered topics such as vibe coding, buying vs building LLMs, automated speech recognition, governmental digital transformation, accessibility, and generative artificial intelligence among others.
About the ACM Technology Policy Council ACM’s global Technology Policy Council sets the agenda for global initiatives to address evolving technology policy issues and coordinates the activities of ACM’s regional technology policy committees in the US and Europe. It serves as the central convening point for ACM’s interactions with government organizations, the computing community, and the public in all matters of public policy related to computing and information technology. The Council’s members are drawn from ACM’s global membership.
About ACM ACM, the Association for Computing Machinery, is the world’s largest educational and scientific computing society, uniting computing educators, researchers, and professionals to inspire dialogue, share resources, and address the field’s challenges. ACM strengthens the computing profession’s collective voice through strong leadership, promotion of the highest standards, and recognition of technical excellence. ACM supports the professional growth of its members by providing opportunities for life-long learning, career development, and professional networking.
UW researchers built AI agents that quickly estimate electronic devices’ carbon footprints
If you shop on Google Flights, you get a quick comparison for different itineraries: One flight’s carbon emissions may be average, while another’s are 14% higher. But if you go shopping for a new laptop, you likely won’t find quick, comprehensible information on different models’ sustainability bonafides, despite thenotable environmental impactsof producing and discarding electronics. In part, that’s because understanding a device’s emissions is difficult and time-consuming, even for experts.
University of Washington researchers developed an artificial intelligence system that automatically estimates the environmental impacts of making different electronic devices. The system uses AI agents — programs that perform tasks autonomously — to comb through publicly available data and conduct life cycle assessments, or LCAs. The system achieves an average error rate of 5%-19%, similar to the accuracy of LCAs conducted by experts.
“Recent studies have shown that people are willing to pay more for more sustainable devices,” said senior authorVikram Iyer, a UW assistant professor in the Paul G. Allen School of Computer Science & Engineering. “So there’s growing demand for this information. But a phone, for example, is made of hundreds of chips and other components, and producing each of those causes varying amounts of emissions. Since that data isn’t public or sometimes not even measured, human experts can spend days, even months manually gathering information for LCA. Instead we designed multiple AI agents that work together to automatically find this data and produce comparable estimates in about a minute.”
AI agents have recently grown increasingly capable of performing complex tasks. Today's agents can search the web and pull information about electronic parts from product descriptions, images and documents.
“Some ofour previous researchmade me curious about how LCA experts perform environmental assessments — and whether that process could be automated,” said lead authorZhihan Zhang, a UW doctoral student in the Allen School. “Sowe interviewed LCA expertsto understand the bottlenecks firsthand, and then built a system that emulates these interactions with two AI agents. Each of them mimics different roles in the LCA process.”
One agent acts as a sort of analyst, defining what information needs to be gathered and how it will fit together. It also reviews results for accuracy. The second agent is more like an engineer. It scrapes publicly available data for information on an electronic device’s components. That might entail sifting through spreadsheets, or looking up images of the insides of devices and taking chip information from them — including from sources not typically used for LCAs, such asFCC databasesand posts oniFixit.
The two agents work in a loop. The first sets the scope, the second gathers information. The first then looks that information over and might send the second agent searching again, and so on. The agents then referenceLCA databasesto convert the complete list of parts to carbon estimates.
The team also developed a new method to bypass this detailed data collection and directly estimate carbon footprints. For common devices like laptops and smartphones with publicly available carbon footprint reports, they found that products with similar specs like screen size and processors clustered around similar carbon values, because only a handful of companies make specialized parts for all these devices. So an unknown device's footprint can be represented as a weighted average of similar products.
They also use this to estimate the carbon for materials not in LCA databases. For example, a new type of sustainable plastic could be estimated based on plastics with similar properties and chemistry.
“We tried this ‘nearest-neighbors’ approach and found that for materials, it’s actually better than the standard approach of a human picking the single closest entry,” said Zhang. “When estimating missing emissions factors in a test, the average error for our method was 23%. Human experts had an average error of 143%.”
The authors note that while the aim of the system is to help reduce carbon emissions overall, running AI models requires energy, so they’ve taken several steps to mitigate its impact. They use small AI models that aren’t as energy-intensive as general-purpose models. They also start the process by running a search to see if the device’s estimated emissions have already been calculated. If so, it can stop there. If the system does need to call its AI models repeatedly, estimating a device’s carbon footprint is currently on par with the emissions generated by brewing a cup of tea.
The team plans to collaborate with companies in the future to help automate their workflows.
“A lot of big companies have sustainability teams that perform these LCAs,” Iyer said. “Our hope is that automating this will actually free up their time, so they can spend their time reducing the carbon footprint of the products themselves, instead of hunting down elusive stats.”
Co-authors includeAlexander Metzger, a UW student in the Allen School;,Felix Hähnlein, a UW postdoctoral researcher in the Allen School;Zachary Englhardt, a UW doctoral student in the Allen School;Shwetak Patel, a UW professor in the Allen School;Yuxuan Meiof Wesleyan University, who completed this research as a UW doctoral student in the Allen School;Tingyu Chengof the University of Notre Dame;Gregory D. Abowdof Northeastern University; andAdriana Schulzof Brown University, who completed this research as a UW assistant professor in the Allen School.
This research was funded by Amazon Research Awards and the National Science Foundation. Zhang was supported by theGoogle PhD Fellowship.
Sheets of molybdenum ditelluride crystals, when stacked on top of one another in a specific way, create the complex lattice structure seen above. In a new study, materials scientists at the University of Washington used artificial intelligence to simulate huge stacks of these sheets, producing new quantum phenomena that were not present at smaller scales.
Quantum materials are a class of exotic materials with special properties that are governed by quantum mechanics rather than classical physics. Those properties — like superconductivity, entanglement and unusual forms of magnetism — often originate in the tiny repeating patterns of atoms inside crystals, but through clever engineering they can be observed and controlled at a more human scale. Quantum materials are helping to power the quickly growing field of quantum computing, and could find their way into future generations of energy-efficient electronics.
Designing new materials from the atomic scale up, however, requires intense modeling and simulation. Some materials may appear ordinary when viewed as small clusters of atoms, yet reveal new and useful properties when their atomic building blocks repeat and interact over larger distances. Researchers must be able to accurately predict behaviors at large scales in order to find materials with practical applications — otherwise designing new materials is a slow and costly trial-and-error process.
In the past 50 years, supercomputers have helped materials scientists solve some of those thorny prediction problems, but two recent studies from the University of Washington demonstrate how newer computing techniques can help researchers sniff out promising quantum materials to pursue. The first study, published June 2 in the Proceedings of the National Academy of Sciences, shows how researchers can use artificial intelligence to simulate dozens of sheets of atoms stacked in intricate patterns, a process that produces complex and potentially useful quantum behaviors. The second study, published June 8 in Nature Communications, shows how quantum computers can create a self-improving design loop by discovering new materials that could themselves be components of future quantum computers.
“What is exciting is that AI and quantum computing are beginning to change not just what problems we can solve, but how we do research,” said Ting Cao, a UW associate professor of materials science and engineering and the senior author of both studies.
These two new tools — AI and quantum computing — are complementary in that they each excel at a different kind of simulation problem. With the right training, an AI model can act as a fast and relatively inexpensive surrogate of a supercomputer, extrapolating the behavior of huge material systems from a relatively small dataset. Cao and collaborators used this approach to stack virtual sheets of atoms on top of one another over and over — a process that created completely new phenomena that were absent on a smaller scale, but would have been impractical to model by traditional supercomputing. From there, researchers can try to make the most promising materials in the lab to prove out the simulations.
Quantum computers, on the other hand, are essentially powered by the same quantum phenomena — like entanglement — that Cao and other materials researchers want to study. Such phenomena can be difficult to simulate using traditional computers or AI systems, but quantum computers are naturally suited to the task. In the study, Cao and his team used a quantum computer to study an exotic phase of matter known as a Laughlin state.
Moving forward, Cao and his team plan to further build out their datasets and eventually develop models that can simulate a much wider range of materials. They also hope to combine their AI and quantum computing systems into a more powerful and flexible hybrid tool.
“The next step is to bring these tools together,” Cao said “We can use AI to guide quantum simulations, and quantum computers to generate new data and insights that improve AI models.”
“We are at the start of a new era,” said Di Xiao, UW professor and chair of materials science and engineering and co-author of both studies. “Our field is fundamentally changing. Things that were literally impossible a couple of years ago are now becoming routine. And we are only beginning to see what AI and quantum computing will make possible for quantum materials.”
The first study was led by Yueyao Fan, a UW doctoral student of materials science and engineering. The second study was led by Lingnan Shen, a UW doctoral student of physics. A complete list of authors is included with the studies.
The authors acknowledge the support of Amazon and the Department of Energy.
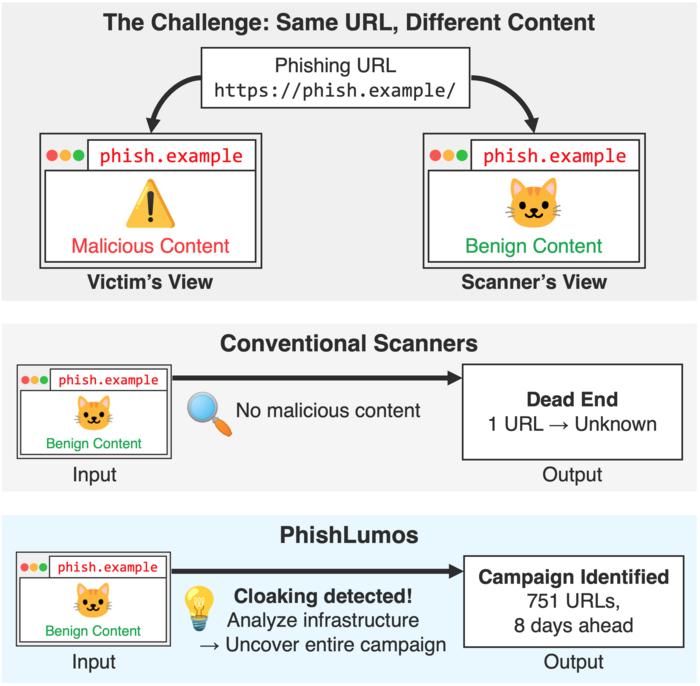
Detecting phishing campaigns when malicious content is cloaked. PhishLumos is triggered when it finds that content is cloaked and uses infrastructure clues to uncover details of the whole phishing campaign.
Tokyo, Japan – Researchers from Tokyo Metropolitan University have created a new paradigm for identifying online phishing campaigns. Their new system, PhishLumos, is triggered when links show signs of concealing information, and looks for clues in the “infrastructure” of the website to uncover the whole campaign of which the site is only a tiny part. Real-world testing showed detection which was 8 days faster than an expert, with 190,000 URLs detected over 6 months.
Phishing is a rampant form of cybercrime. Criminals impersonate trusted entities like banks or employers to get victims to share sensitive information, click malicious links, or install harmful software. Less digital savvy people are at particular risk, which not only widens the digital divide but erodes trust in essential digital institutions.
This is why researchers have been looking for ways to shut down phishing campaigns. However, they face severe challenges. For example, most existing approaches involve analyzing individual, suspicious links on the web, or Uniform Resource Locators (URLs). While machine learning and deep learning approaches have helped realize increasingly sophisticated programs that can assess content for veracity, cybercriminals can generally produce far more malicious links in the same time it takes to identify and shut down one site. Malicious content generation is also becoming cleverer; cloaking technologies can help fool scanners, leading to more malicious content making it in front of potential victims.
Now, researchers are looking for a paradigm shift. In recent work, a team led by Associate Professor Daiki Chiba from Tokyo Metropolitan University has adopted a new approach. Rather than trying to label single links as good or bad, they look for signs of cloaking as a starting point for a whole, automated investigation to identify the whole phishing campaign associated with a malicious actor. Their system, PhishLumos, is not evaded by withheld content, but triggered instead. Once activated, it will look for clues in the “infrastructure” of the URL, like which Internet Protocol (IP) numbers are involved, and which network connections are used. These help map out the whole campaign of URLs involved in the same phishing project, not simply as a big list of URLs, but a so-called Knowledge Base (KB) graph which describes how the campaign works.
Looking at 103 real phishing campaigns, PhishLumos was able to achieve detection 8 days faster than experts on average. In real-world tests, given 600 seed URLs as starting points, the rules that it uncovered led to the discovery of over 190,000 new links of which 92% were later flagged as malicious. Importantly, it significantly outperformed so-called “content-centric” approaches which go through website content instead of infrastructure clues.
Online services are already an indispensable part of modern society, so bad actors can cause widespread, irreparable harm to society. Projects like PhishLumos are an essential part of making sure that the benefits of new information technologies reach everyone in a safe and fair way.
The proposed method combines a graph neural network with hierarchical clustering to extract key features linking crystal structure to optical spectra, and then groups materials with similar structural and spectral characteristics, revealing patterns that can guide materials design.
A method to interpret artificial intelligence (AI) models used in materials discovery by analyzing their learned features has been developed by researchers from Japan. The method extracts key features from an AI model trained on atomic structural data and optical absorption spectra, and then groups materials with similar structural and spectral characteristics. This approach can be extended to reveal how atomic arrangements influence other material properties, paving the way for more efficient materials design.
In recent years, artificial intelligence (AI) has emerged as a powerful tool to predict how materials will behave based on their atomic structure, helping researchers discover new materials faster and reduce reliance on trial-and-error methods. However, many of these models work like “black boxes.” They can make accurate predictions, but they do not explain how those predictions are made. This makes it difficult to understand the relationships between a material’s structure and its properties, limiting how useful these models are for guiding the development of new designs.
Now, in a study to be published in the journal Advanced Intelligent Discovery on June 15, 2026, researchers from Institute of Science Tokyo (Science Tokyo), Japan, have developed a method to make these models more interpretable. Their approach works by analyzing a trained AI model and extracting the key features it has learned about how crystal structure relates to optical spectra. Using these features, the researchers then grouped materials that share similar optical spectra and structural characteristics.
The study was led by Assistant Professor Akira Takahashi, Professor Fumiyasu Oba (also a project leader at KISTEC, Japan), and Master’s course student Arata Takamatsu (at the time of the research) of the Materials and Structures Laboratory, Science Tokyo, in collaboration with Professor Yu Kumagai of the Institute for Materials Research, Tohoku University, Japan.
“Our proposed classification method allows for an understanding in detail of how AI prediction models make predictions, namely, extracting key factors for desired spectral shapes, and thereby providing useful physical and chemical insights for materials design,” says Takahashi.
Material’s properties often depend on some parameters and are described using spectral data—for example, optical absorption spectra capturing how light interacts with the material across different wavelengths. Compared to properties represented by a single number, spectral data are far richer and more complex, making them challenging to interpret using conventional AI methods.
The researchers used an atomistic line graph neural network (ALIGNN), an existing graph neural network architecture, trained to predict optical absorption spectra from atomic structure using data from 2,681 metal oxides, chalcogenides, and related compounds. From the trained model, they extracted features from its internal layers and applied hierarchical clustering, a method that groups items based on similarity. This allowed them to classify materials into distinct groups that shared both structural features, such as elemental composition, atomic coordination, bond lengths, and bond angles, and similar spectral shapes.
Notably, the model learned these patterns from atomic structure alone, without being given oxidation states or electronic configurations as input, indicating that it had internally captured meaningful relationships between structure and properties.
Optical properties play a key role in many applications. They affect a material’s appearance, which is important for pigments and dyes, and govern how it interacts with light in devices such as solar cells and photodetectors. Understanding which elemental species and structural features shape these spectra is, therefore, key to establishing rational design guidelines for such materials.
Furthermore, the approach is not limited to optical spectra: it can be extended to determine how a material’s structure influences its behavior under different conditions, such as temperature or pressure, opening up new possibilities for designing materials with specific and useful properties. As demonstrated here for optical absorption, the approach can be applied to a range of spectral properties, enabling researchers to identify common factors shared by different materials and infer the origins of desired spectral characteristics.
“It has been difficult to interpret what machine learning models have learned about spectral properties. In this work, we developed a general method to extract such insights, which we believe will prove broadly useful for materials research,” concludes Takahashi.
***
About Institute of Science Tokyo (Science Tokyo)
Institute of Science Tokyo (Science Tokyo) was established on October 1, 2024, following the merger between Tokyo Medical and Dental University (TMDU) and Tokyo Institute of Technology (Tokyo Tech), with the mission of “Advancing science and human wellbeing to create value for and with society.”
Deep Learning-Based Extraction of Promising Material Groups and Common Features from High-Dimensional Data: A Case of Optical Spectra of Inorganic Crystals
Article Publication Date
15-Jun-2026
COI Statement
The authors declare no conflicts of interest.
Rockefeller University Press partners with Cashmere for responsible AI discoverability
Partnership uses Cashmere’s infrastructure suite to enable safe, controlled and transparently reported AI inference use of Rockefeller University Press journals
Rockefeller University Press (RUP) has partnered with Cashmere, a data infrastructure platform, to manage the integration of its scientific literature into AI-powered research applications. The collaboration establishes a secure and transparent framework for AI inference, which is the phase in which a trained AI model queries live data to answer user questions and generate real-time results. The partnership ensures that RUP’s peer-reviewed content is accurately represented and discoverable to scientists who are using AI tools while simultaneously protecting that same content from unauthorized training use.
Through the partnership, RUP will make Journal of Cell Biology (JCB), Journal of Experimental Medicine (JEM), Journal of General Physiology (JGP), and Journal of Human Immunity (JHI) available for AI inference use cases. The arrangement ensures that AI applications can access RUP content within clearly defined licensing boundaries. RUP retains full visibility into how its content is used, by whom, and to what commercial effect, with detailed usage analytics and transparent revenue reporting delivered through the Cashmere platform.
“Life sciences is one of the domains where the quality and provenance of AI’s source material matters most," says Jonathan Munk, CEO, Cashmere. "When a clinician, researcher, or AI agent draws on a journal article to inform a decision, they need to know that content is peer-reviewed, current, and legitimately licensed. Rockefeller University Press has been producing exactly that kind of authoritative science for generations. Our partnership makes that content available to AI developers on terms that are clear, enforceable, and fair, and gives RUP the visibility and revenue transparency they deserve as a content partner in the inference economy.”
The partnership builds on Cashmere’s growing network of leading publishers and AI platforms, and it reflects broader momentum across the scholarly publishing sector to establish principled frameworks for AI content licensing.
“Rockefeller University Press has been committed to the widest possible dissemination of rigorous science, and AI represents a new channel through which researchers, clinicians, and developers engage with biomedical knowledge," says Rob O’Donnell, Senior Director of Publishing, Rockefeller University Press. "This partnership with Cashmere allows us to participate in that channel with confidence. We can view how our content reaches AI applications through a framework that respects our authors’ work, enforces appropriate licensing, and gives us genuine insight into how our publications are being used and the value they are generating. It is the kind of controlled, transparent approach that scholarly publishing needs to embrace the AI era responsibly.”
About Rockefeller University Press
Rockefeller University Press is committed to quality and integrity in scientific publishing. RUP publishes Journal of Cell Biology (JCB), Journal of Experimental Medicine (JEM) and Journal of General Physiology (JGP), and co-owns Journal of Human Immunity (JHI) and Life Science Alliance (LSA). We use the latest technologies and carry out rigorous peer review, applying the highest standards of novelty, mechanistic insight, data integrity, and general interest to fulfill our mission of publishing excellent science. RUP’s journals were established by the research community, and editorial decisions and policies continue to be driven by scientists who actively contribute to their fields, appreciate the value of peer review, and desire a better publication experience for all. Learn more at rupress.org.
About Cashmere
Cashmere is a data infrastructure platform that connects premium content publishers with AI companies. Built on its proprietary OmniPub infrastructure, Cashmere enables publishers to protect, license, and monitor their intellectual property while unlocking new revenue streams in the AI economy. Cashmere’s $5M seed round was led by Reach Capital, with participation from a group of strategic industry partners. For more information, visit www.cashmere.io. Contact press@cashmere.io.



No comments:
Post a Comment